

The Network and Information Systems 2 (NIS2) Directive, formally Directive (EU) 2022/2555, builds on the original NIS Directive (2016/1148), which was enacted in 2016 to establish a common level of cybersecurity across the European Union (EU).
The European Parliament and Council created NIS2 to respond to evolving cybersecurity threats driven by the wider organizational adoption of cloud and AI technologies. It expands the scope to cover more sectors across public and private institutions. It also sets clearer, stronger rules for cybersecurity risk management, incident reporting, and enforcement across all EU member states. These enhanced measures aim to better safeguard critical infrastructure and essential services against increasingly sophisticated cyberattacks.
To guide organizations with NIS2 compliance, this comprehensive guide covers NIS2’s expanded scope, new requirements, enforcement, alignment with other frameworks, and national implementation variations.
It offers practical insights for CISOs, compliance leaders, and business owners on managing cyber-risk effectively and maintain compliance to the new mandate.
What is NIS2? An Overview and General Understanding
The NIS2 Directive is the EU’s updated framework for improving cybersecurity across its member states. The directive establishes a common legal framework aimed at securing network and information systems in 18 critical sectors, including energy, transport, healthcare, finance, digital infrastructure, and public administration.
The directive requires in-scope entities to adopt an all-hazards approach, meaning they must be equipped to manage a broad spectrum of risks – from cyber incidents to physical disruptions – to ensure operational resilience and comprehensive security.
Official Effective and Compliance Dates of NIS2
NIS2 was adopted in December 2022 and took effect at the EU level in January 2023, and EU member states were required to transpose it into national law by Oct. 17, 2024. Organizations were mandated to comply with the new requirements as soon as national laws were put in place, which began in late 2024 and into 2025.
Member states were also tasked with establishing and regularly updating a list of essential and important entities by April 17, 2025, and every two years thereafter.
How is NIS2 a Continuation of NIS1?
NIS2 sets higher standards than its predecessor by expanding the scope of entities subject to its requirements, particularly including medium-sized and large organizations within the covered sectors. It mandates stronger cybersecurity risk management measures, compulsory incident reporting within strict deadlines, and enhanced cooperation among member states.
A key aspect of NIS2 is the obligation for each member state to adopt a national cybersecurity strategy and maintain up-to-date lists of essential service operators, ensuring they comply with the regulation. The directive also introduces differentiated supervision regimes for essential and important entities, with essential entities subject to proactive supervision and important entities more reactive monitoring.
NIS2’s Scope: Affected Sectors
The original NIS directive targeted critical sectors like energy, transport, and healthcare. The NIS2 Directive broadens the scope of the covered sectors and divides them into two main categories: essential and important entities. This distinction helps tailor the level of cybersecurity requirements and supervision depending on the criticality of the service provided.
Essential entities are considered vital for the functioning of the economy and society, and their disruption could have significant impacts. These include sectors such as energy, transport, banking, healthcare, and digital infrastructure.
Important entities, while still crucial, are deemed to have a somewhat lower risk profile and include sectors like certain manufacturing industries, postal and courier services, and wastewater management.
Under Article 3 and Annex 1 of NIS2, essential entities such as those in energy, transport, banking, and healthcare face the highest level of scrutiny and stricter compliance requirements compared to important entities.
Here is how the industries break down under each category:
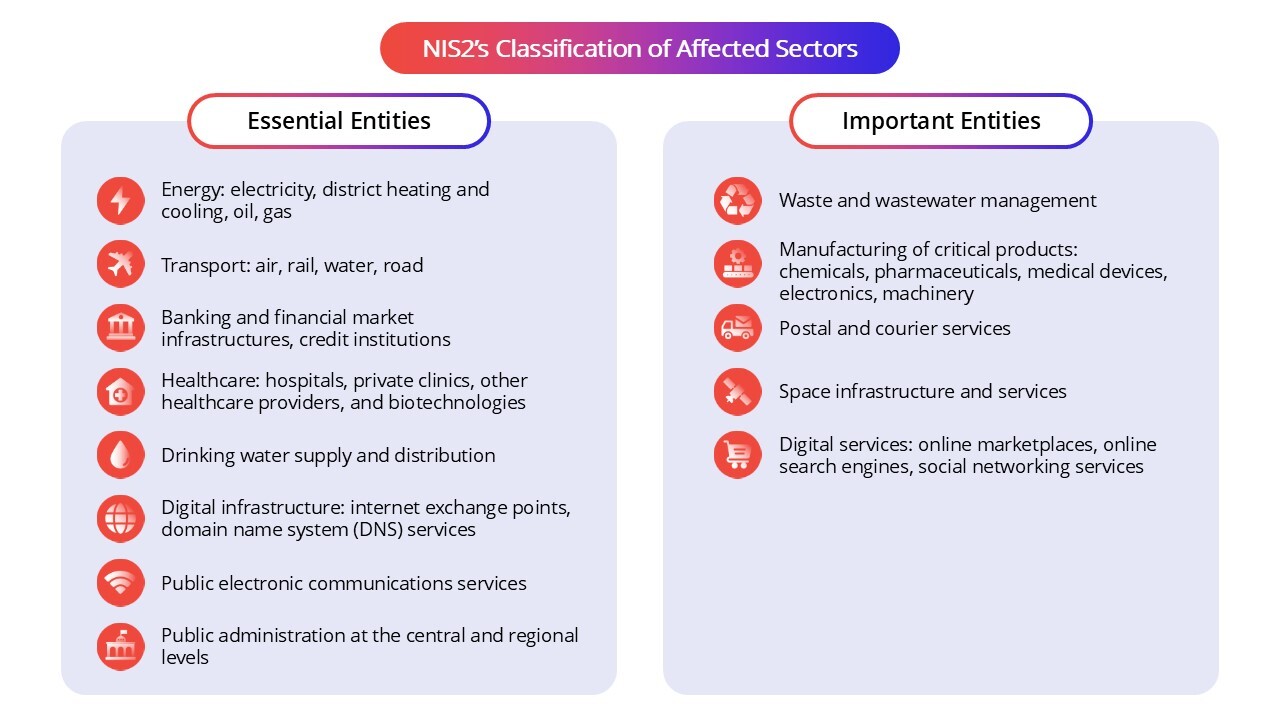
This classification ensures that the most critical sectors face the highest level of cybersecurity scrutiny, while still improving protection across a wide range of industries important to the EU's digital and physical infrastructure.
NIS2 Requirements
The NIS2 Directive outlines clear and stringent cybersecurity requirements that all in-scope organizations must meet. The main obligations include:
- Risk management measures. Organizations must implement appropriate technical and organizational measures to prevent and minimise risks. This includes incident prevention, multi-factor authentication (MFA), encryption, vulnerability handling, and regular security assessments.
- Incident reporting. NIS2 mandates organizations to provide early warnings within 24 hours of detection, followed by a detailed report within 72 hours and a final comprehensive report within one month.
- Business continuity and crisis management. Entities must establish and maintain plans for business continuity and disaster recovery to ensure operational resilience during and after cyber incidents. These plans should cover system recovery, emergency procedures, and crisis response team readiness.
- Corporate governance and accountability. Senior management is held directly accountable for cybersecurity and compliance. They must oversee cybersecurity strategies and ensure proper staff training to ensure alignment across the organization. Failure to do so can lead to penalties, including temporary bans from management roles.
Emphasis on Supply-Chain Security
A crucial area of increased focus in NIS2 is on supply chain security. According to Article 21 (2) (d) of the Directive, all organizations doing business with EU-based enterprises, including security-related aspects concerning the relationships between each entity and its direct suppliers or service providers, must ensure their own cybersecurity measures align with NIS2 requirements, creating a more secure and resilient network ecosystem across and beyond the EU.
For practical compliance guidance, AvePoint offers a comprehensive NIS2 Checklist to help organizations navigate these requirements effectively.

NIS2 Compliance
Implementing the NIS2 Directive requires coordinated efforts both at the national and organizational levels to achieve full compliance and strengthen cybersecurity resilience.
At the organizational level, executives should follow these key steps:
1. Determine the scope and impact. Understand whether your organization is categorized as an essential or important entity to ensure your compliance efforts will align with NIS2’s regulatory requirements.
2. Conduct risk assessments. Evaluate cybersecurity threats and vulnerabilities across your networks, systems, and supply chains to understand where the highest risks lie and prioritize mitigation efforts.
3. Develop cybersecurity policies. Establish clear and comprehensive policies that address risk management, incident reporting, business continuity, and governance to guide consistent security practices organization-wide.
4. Assign leadership accountability. Ensure senior management actively oversees and takes responsibility for cybersecurity strategy, compliance, and employee training, reflecting NIS2’s emphasis on corporate governance.
5. Implement technical controls. Deploy security measures such as MFA, encryption, network monitoring, vulnerability management, and comprehensive cloud backup to protect critical assets and reduce attack surfaces.
6. Establish incident reporting procedures. Create streamlined processes to promptly report cybersecurity incidents to authorities within the strict deadlines mandated by NIS2 regulations.
7. Plan for business continuity and disaster recovery. Prepare crisis management and emergency response plans to maintain essential functions and quickly restore systems after cyber incidents. The best recovery is no recovery at all. Build true data resilience by taking proactive steps to protect and govern your data before disaster strikes.

8. Ensure cooperation from supply chain partners. Make cybersecurity compliance mandatory for vendors and partners to secure interconnected systems, limiting risks posed by third parties.
9. Establish continuous training and awareness programmes. Provide regular, role-specific cybersecurity training for all staff, including leadership, aligned with NIS2. Cover incident reporting, risk management, cyber hygiene, and response roles to reduce human error and strengthen overall resilience.
10. Conduct regular internal audits and assessments. Schedule and perform frequent audits to evaluate the effectiveness of implemented cybersecurity measures, policies, and controls. Use these assessments to identify gaps, ensure alignment with NIS2 requirements, and prepare for external inspections by supervisory authorities.
The directive also emphasizes cross-border cooperation through mechanisms such as the European Cyber Crises Liaison Organisation Network (EU-CyCLONe), which coordinates responses to large-scale cybersecurity incidents and facilitates information sharing between member states.
Following these steps helps organizations not only bolster their cybersecurity stance but also supports better governance of data, network infrastructure, and systems, thereby reducing the risk of costly penalties for non-compliance.
Enforcement, Penalties, and Governance
The enforcement of the NIS2 Directive is primarily the responsibility of national competent authorities designated by each EU member state. These authorities are responsible for supervising both essential and important entities to ensure compliance with the directive's provisions.
Proactive and Reactive Supervisory Frameworks
Supervisory frameworks include proactive supervision for essential entities, involving regular and targeted audits, on-site and off-site inspections, security scans, and requests for documentation. For important entities, supervision tends to be reactive, triggered by indications of potential non-compliance. These authorities have broad powers to issue compliance orders, binding instructions, and to demand the implementation of security audits and remedial measures.
Penalties and Sanctions for Non-Compliance
Penalties for non-compliance are significant and are detailed mainly in Articles 32 and 33 of the directive.
These enforcement measures and penalties aim to ensure effective adherence to NIS2, strengthening cybersecurity across the EU and encouraging organizations to prioritize robust risk management and incident reporting processes. Penalties and sanctions are summarized below:
| Type of Entity | Administrative Fines |
| Essential | Fines of up to €10 million or 2% of their global annual turnover, whichever is higher |
| Important | Fines of up to €7 million or 1.4% of global turnover |
Besides administrative fines, non-monetary sanctions include public disclosure of violations, temporary bans on management personnel, and orders to cease certain activities. The directive notably holds senior management personally liable for gross negligence in cybersecurity governance, underscoring the importance of leadership accountability.
How NIS2 Compares with Other Cybersecurity Frameworks and Standards
Certain aspects of the NIS2 Directive align with other key cybersecurity and data protection frameworks like the GDPR, the Digital Operational Resilience Act (DORA), and ISO 27001, reflecting its specific focus and scope within the EU regulatory landscape. Below, we discuss how NIS2 compares with these frameworks to show how NIS2 integrates with, supports, and differs from them.
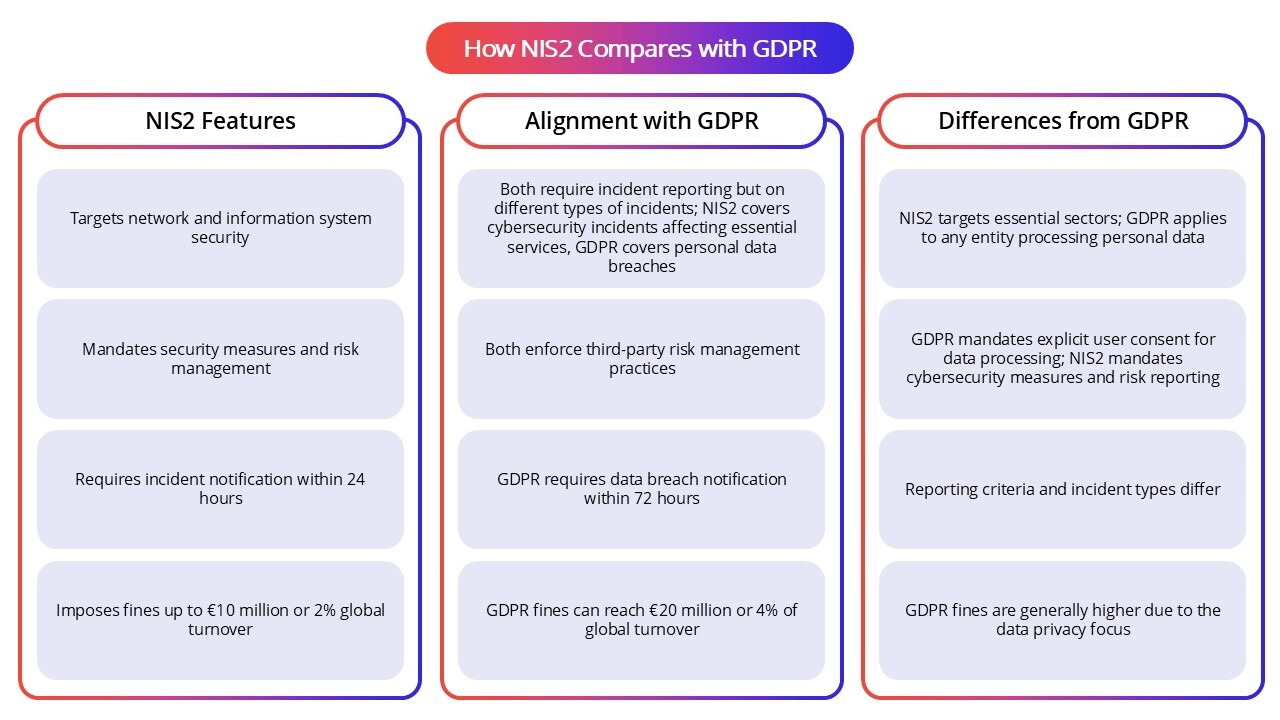
How NIS2 Compares with GDPR
NIS2 shares with GDPR a strong emphasis on data protection and incident reporting but is focused more broadly on network and information system security across critical sectors. Both set out strict requirements for early notification of breaches, but GDPR centers on the privacy of personal data, whereas NIS2 mandates resilience and security measures for essential and important entities.
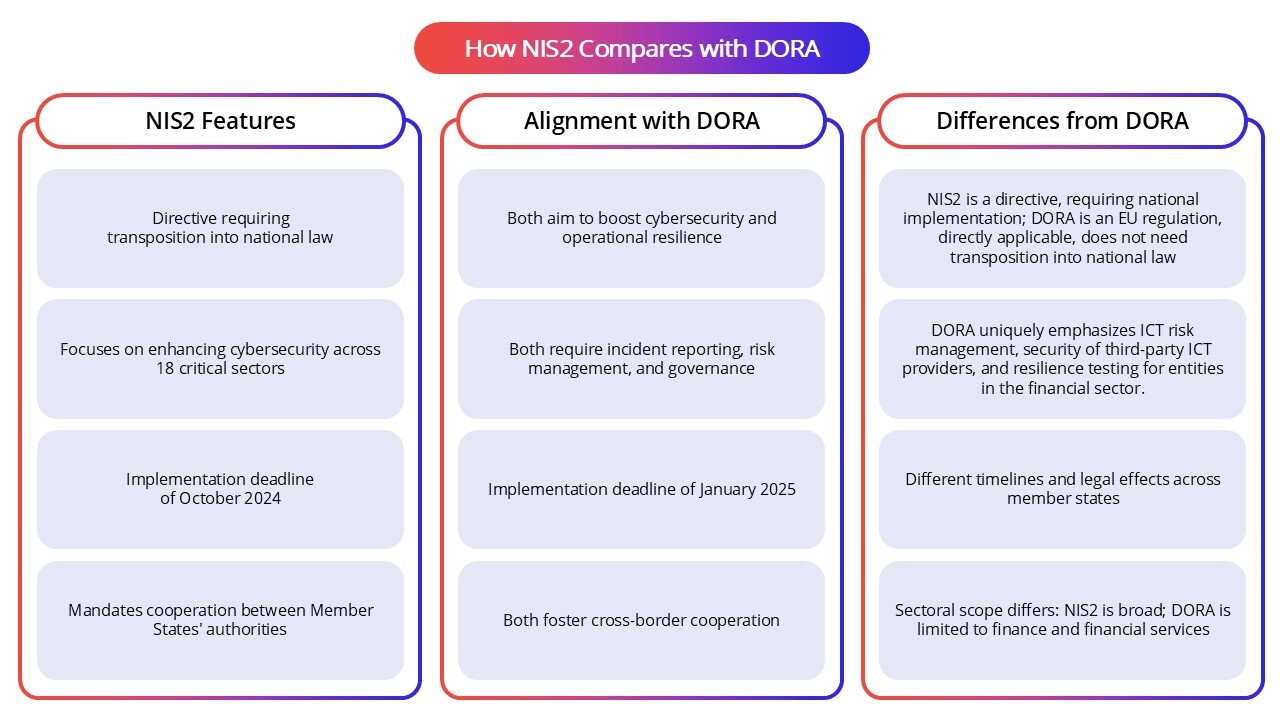
How NIS2 Compares with DORA
DORA is an EU regulatory framework specific to the financial sector, focusing on operational resilience and ICT risk management. Meanwhile, NIS2 broadly covers critical infrastructure sectors beyond finance.
Both require strong governance and risk management but differ in incident reporting timelines and resilience testing requirements. DORA mandates more frequent resilience testing and stricter reporting timelines, while NIS2 emphasizes cross-sector harmonization of cybersecurity practices.
How NIS2 Compares with the EU’s Cyber Resilience Act (CRA)
While both NIS2 and the CRA aim to strengthen cybersecurity in the EU, their focus and application differ significantly. NIS2 centers on ensuring robust cybersecurity measures and incident response among organizations providing essential and important services across critical sectors. In contrast, the CRA targets the security of products with digital elements – both hardware and software – placed on the EU market, emphasizing security-by-design requirements throughout the product lifecycle. Together, they form complementary parts of the EU’s overarching cyber strategy, addressing security from the perspective of both service providers and product manufacturers.
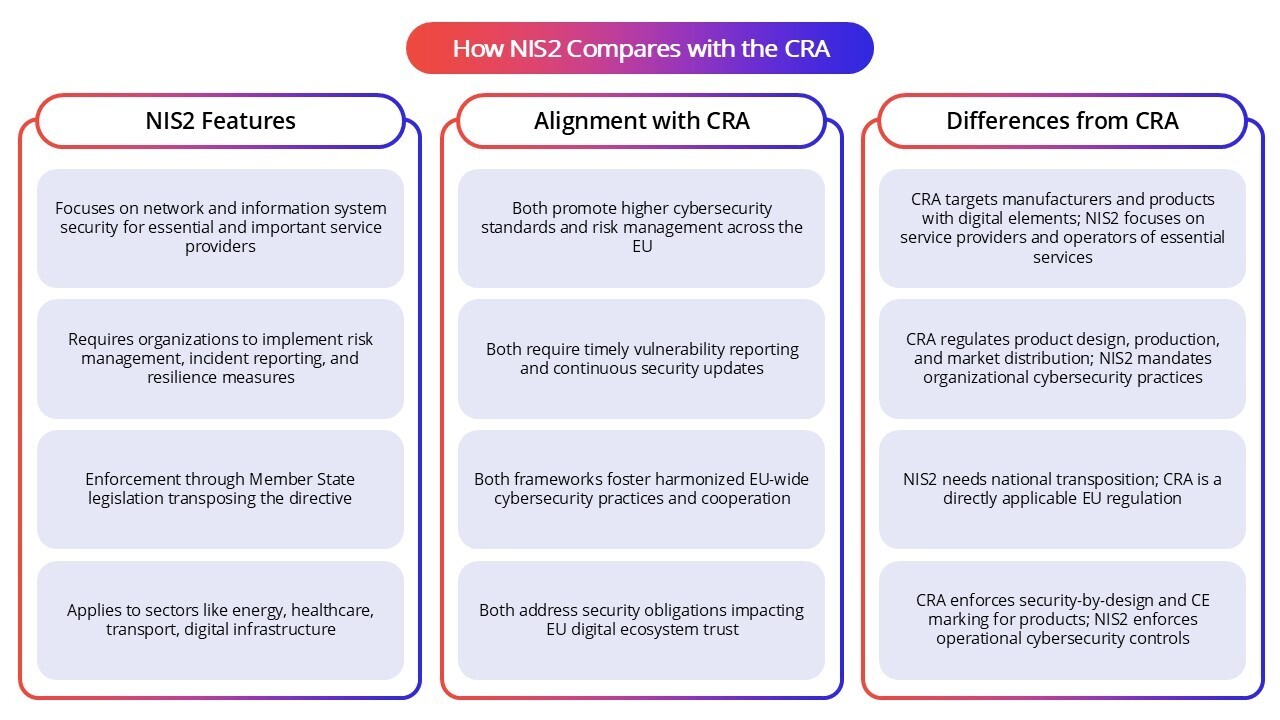
How NIS2 Compares with the EU AI Act
The EU AI Act (Regulation (EU) 2024/1689)adopts a risk-based framework to regulate the development, deployment, and use of AI systems, ensuring they are safe, transparent, and respect fundamental rights such as non-discrimination and human oversight. Unlike NIS2, which applies to critical service operators and their networks, the AI Act focuses on the AI systems themselves, and the entities involved in their lifecycle, such as providers, deployers, importers, and distributors. It also emphasizes preventing bias and maintaining high data quality.
These regulations intersect importantly for organizations providing critical services under NIS2 that use high-risk AI systems regulated by the AI Act. The AI Act requires these systems to be designed with robust cybersecurity to withstand adversarial attacks. NIS2, in turn, mandates securing the networks and infrastructure hosting these AI systems. Together, they establish a complementary security strategy. Both laws require strong risk management and incident reporting, although their specific procedures and timelines differ.
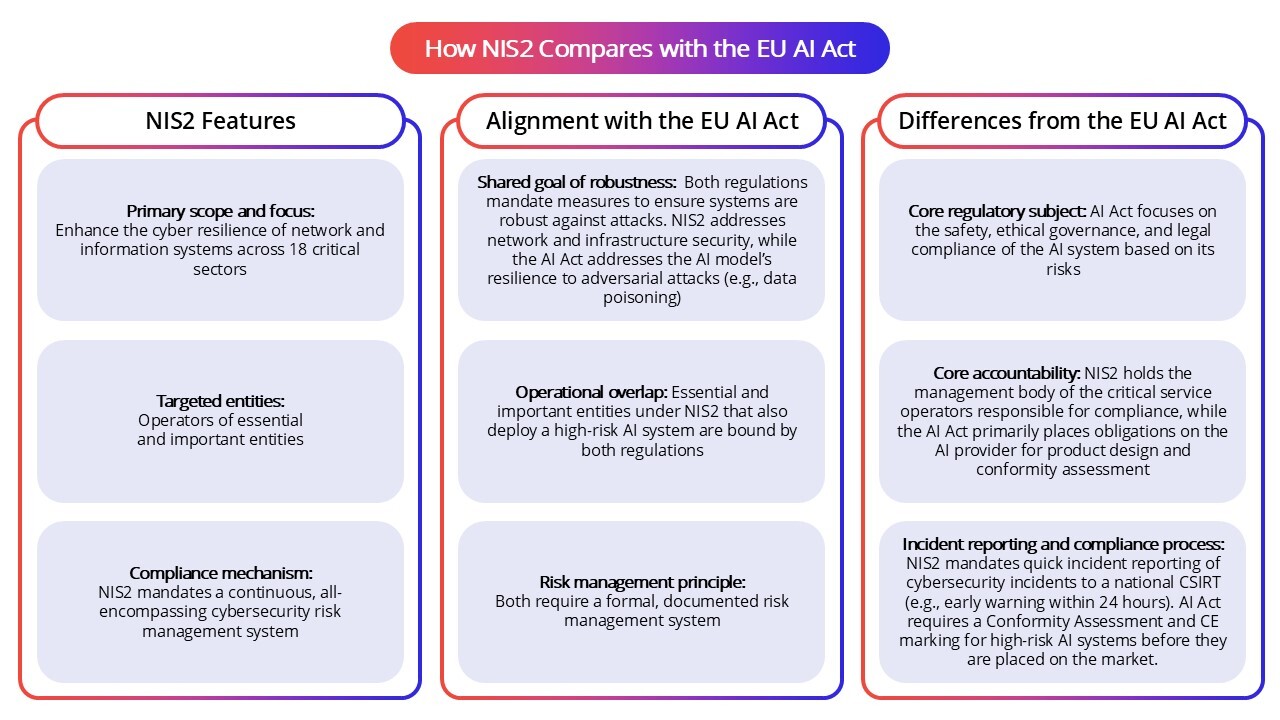
How NIS2 Compares with ISO 27001
ISO 27001 is an internationally recognized standard for information security management systems. NIS2 complements ISO 27001 by setting EU-wide legal requirements designed to ensure a baseline of cybersecurity risk management and governance. While ISO 27001 provides a voluntary framework and certification for continuous improvement, NIS2 enforces legal obligations with penalties for non-compliance, including mandatory incident reporting, which ISO 27001 does not demand.
Together, these frameworks complement one another, with NIS2 providing legal enforcement for EU-wide cybersecurity hygiene and resilience, GDPR safeguarding personal data, ISO 27001 offering mature security management best practices, and DORA focusing on the unique operational risks of the financial sector. This layered approach ensures that entities across different sectors can strengthen their cybersecurity posture while meeting overlapping regulatory requirements efficiently.
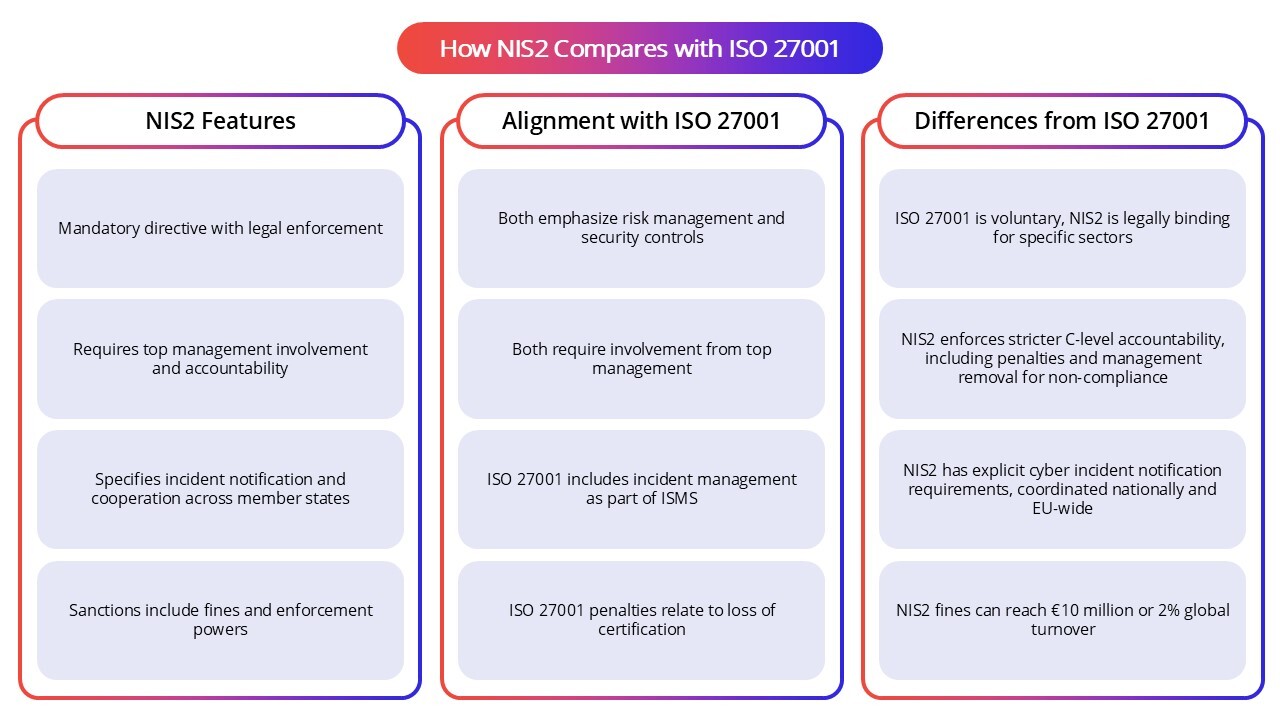
How NIS2 Compares with the System and Organization Controls (SOC 2) Framework
SOC 2 is a voluntary auditing framework developed by the American Institute of Certified Public Accountants (AICPA) focusing on the security, availability, confidentiality, processing integrity, and privacy of service providers’ systems. NIS2, on the other hand, is a binding EU directive that establishes mandatory cybersecurity requirements for essential and important entities across critical sectors. While SOC 2 emphasizes market trust and third-party assurance, NIS2 enforces legal obligations with penalties and requires incident reporting aligned with EU-wide cybersecurity objectives.
Localizing NIS2 Implementation
While some countries have fully enacted their legislation in compliance with the mandate to transpose the NIS2 Directive into a national law by Oct. 17, 2024, others are still drafting or have limited public information about their implementation progress. This has led to a varied landscape across Europe, where the scope, obligations, and supervisory details differ by country, reflecting specific national legal traditions and priorities. Despite these differences, the directive aims to uphold a consistent baseline of cybersecurity across the EU and foster cooperation among member states.
EU Member States
Below are key points on NIS2 implementation in major EU countries:
Germany
- NIS2 Implementation Act (NIS2UmsuCG) is expected to come into force in early 2026
- Current drafts have been developed by the Federal Interior Ministry, with public consultations ongoing
- Existing Critical Infrastructure regulations (KRITIS) largely remain and are integrated into the NIS2 framework
- German implementation includes specific definitions for essential and important entities
- Public administration scope is narrower, mostly limited to federal administration
- Delay in formal enactment has led to EU infringement proceedings against Germany
France
- Draft implementation was adopted by the Senate in March 2025 and is under review by National Assembly
- France combines NIS2, DORA, and Critical Entities Resilience (CER) in a unified legislative framework focused on resilience
- Scope expanded to include local authorities and educational institutions involved in research
- Overseen by the National Agency for the Security of Information Systems (ANSSI)
- The Senate adopted the NIS2 transposition bill in March 2025, but it still needs examination by the French National Assembly. The European Commission sent France a reasoned opinion in May 2025 for failure to notify full transposition. Transposition is now expected by the end of 2025 or early 2026.
Italy
- Legislative Decree 138/2024was enacted on Oct. 16, 2024, and is progressively applicable with future enactments planned
- Scope expanded to 18 sectors; includes additional public administration and educational institutions
- Registration for digital providers concluded around Dec 2024 – Jan 2025) and other entities at around Dec 2024 – Feb 2025
- Full compliance obligations expected by October 2026
- Safeguard clause allows for specific derogations under certain conditions
Spain
- Legislative draft approved last January 2025, aiming to merge NIS2 and CER into a single cybersecurity governance law
- The draft law merging NIS2 and CER is still under urgent legislative review, with the government aiming to finalize it soon to avoid EU sanctions for delays
- The National Cybersecurity Centre (CNCS) was created as a central supervisory authority
- Scope significantly expanded from under 1,000 to around 12,000 entities across 18 sectors
- Entities are divided into “essential” and “important” based on size and turnover thresholds
- Public entities are exempt from fines but must comply
Netherlands
- Public consultation for the Draft Cybersecurity Act closed last June 2024and is being revised based on consultation feedback
- The law is anticipated to be enacted during the second quarter of 2026
- Interim application means only previously covered entities must comply until the new law takes effect
- The law focuses on ICT risk management, incident reporting, and domain name registration compliance
Sweden
- Government proposal currently under consultation; bill expected by autumn 2025
- New Cyber Security Act is proposed to take effect on 15 January 2026
- Expands obligations in line with NIS2 across essential sectors including research institutions
- Stricter incident reporting timelines and national security baselines set by the Swedish Civil Contingencies Agency
Poland
- Building upon the existing 2018 National Cybersecurity Act by adding a NIS2 chapter (KSC-2)
- Expansion of regulated entities from 400 to over 10,000
- High sanctions cap: up to €10 million or PLN 100 million in critical cases
- Mandatory entity self-classification as essential or important, impacting compliance levels and oversight
- Compliance deadlines expected early 2026
Belgium
- NIS2 Law was published in May 2024, and took effect in October 2024
- Replaces prior NIS1 legal framework, transposing EU minimum requirements
- Coordinated by Centre for Cybersecurity Belgium (CCB)
- Closely aligned with EU text, minor national variations only openkritis
UK’s Alignment with NIS2 Standards
Although not an EU member, the UK is actively strengthening its cybersecurity framework in parallel with NIS2 developments. UK organizations with business ties to the EU must navigate both domestic requirements and cross-border obligations.
The UK's Network and Information Systems Regulations 2018 remain the primary legal framework, but significant changes are underway. The UK Cyber Governance Code of Practice, published by the Department for Science, Innovation and Technology, now provides boards and directors with guidance on managing cyber security risks. The Code aligns with international standards including NIST in the US, ISO/IEC 27001, and the UK’s National Cyber Security Center’s (NCSC) Cyber Assessment Framework, and is recommended by the government as the key resource for boards preparing for upcoming legislative requirements.
Looking ahead, the UK Cyber Security and Resilience Bill anticipated for enactment in 2026 will transform cyber governance from best practice into legal obligation. The Bill will strengthen board-level accountability, expand incident reporting requirements, and enhance supply chain oversight. These provisions align closely with NIS2 principles and the Digital Operational Resilience Act (DORA), creating consistency across UK and EU cybersecurity frameworks. It must be noted that pending the finalizationa and enactment of the Bill, there could be necessary amendments to related cybersecurity legislations like the UK's Network and Information Systems Regulations 2018.
For UK organizations operating in or with EU sectors, this means:
Compliance with cross-border cybersecurity cooperation and incident reporting consistent with EU partners
Preparation for heightened board-level accountability under the upcoming Bill
Implementation of the Cyber Governance Code's principles to meet both current best practices and future legal requirements
Alignment with NIS2 and DORA standards to ensure interoperability and continued market access across regions
The convergence of UK and EU cybersecurity requirements signals a coordinated approach to managing digital risks across interconnected economies.
NIS2 Directive FAQs
Here are the most frequently asked questions about NIS2 for EU-based organizations:
What are the main objectives of NIS2?
The NIS2 Directive is a key regulation designed to strengthen cybersecurity resilience across the EU’s critical infrastructure. It establishes a unified framework requiring organizations to effectively manage ICT security risks, enhance incident response and reporting, and implement robust business continuity plans. By enforcing these standards, NIS2 aims to protect essential and important sectors from increasingly sophisticated cyberthreats, ensuring a higher and more consistent level of cybersecurity throughout the EU.
Which organizations fall under NIS2's scope, and what are the size requirements?
NIS2 covers medium and large-sized entities across 18 critical sectors, including energy, transport, healthcare, digital infrastructure, and manufacturing. The directive introduces clear size thresholds rather than leaving classification entirely to member states. Essential entities face stricter supervision, while important entities have lighter regulatory requirements. Member states retain discretion to include smaller high-risk entities.
What types of organizations are exempt from NIS2?
Organizations typically exempt from NIS2 are small or micro-enterprises with fewer than 50 employees and an annual turnover below €10 million. However, exemptions vary by sector and national rules. Smaller entities may still fall under NIS2 if they provide essential services or are sole providers in their country. The directive primarily targets medium and large organizations in critical sectors, requiring them to meet strict cybersecurity standards. Some smaller entities may also be included if their operations have significant societal or economic impact.
Does NIS2 affect non-EU organizations?
Yes, the NIS2 Directive absolutely affects non-EU organizations. It has an extraterritorial effect, meaning it applies to companies located outside the EU if they provide essential or important services within the EU. Non-EU companies falling under its scope, such as certain digital service providers, must comply with all risk management and incident reporting obligations. Also, all entities in the supply chain of a critical EU operator may be indirectly subject to its security standards regardless of their own location.
What are the mandatory cybersecurity requirements under NIS2?
Organizations must implement 10 key security elements, including incident handling, supply chain security, vulnerability management, cryptography, and access control. A risk-based approach with appropriate technical and organizational measures is required. The directive mandates regular risk assessments and ensures cybersecurity measures are proportionate to identified threats.
What are NIS2's incident reporting obligations and timelines?
Early warning must be submitted within 24 hours of becoming aware of a significant incident. Detailed incident notification follows within 72 hours, with a comprehensive final report required within one month. Reports go to national computer security incident response teams (CSIRTs) or competent authorities, who can provide operational assistance if requested.
How is NIS2 supervised and enforced?
NIS2 is enforced by national authorities in each EU member state, which are granted strong supervisory powers. These include conducting audits, issuing binding instructions, and imposing administrative fines of up to €10 million or 2% of global annual turnover. Authorities can also hold management personally accountable, with penalties such as temporary bans from leadership roles. Enforcement ensures that essential and important entities comply with cybersecurity obligations to protect critical infrastructure and services.
What penalties and sanctions apply for non-compliance?
Essential entities face maximum fines of €10 million or 2% of worldwide annual turnover, whichever is higher. Important entities face maximum fines of €7 million or 1.4% of worldwide turnover. Senior management personnel face personal liability for cybersecurity failures. Sanctions include binding instructions and mandatory security audits.
When must organizations comply with NIS2 requirements?
Most EU countries have already implemented their national legislation. Organizations should assess their compliance status immediately as enforcement is now active. Late compliance carries the full range of administrative penalties and supervisory measures outlined in the directive.
How does NIS2 address supply chain and third-party risk management?
NIS2 requires organizations to address cybersecurity risks in supply chains and supplier relationships as one of the mandatory 10 security elements. Companies must conduct thorough risk assessments for all vendors throughout the supply chain and implement security measures tailored to each direct supplier's vulnerabilities. This includes assessing overall security levels across all suppliers and maintaining ongoing monitoring of third-party cybersecurity posture.
