




Want more Project Cortex insights? Check out the full webinar “Next Level Knowledge Management in Office 365: Project Cortex, Yammer Communities, and Records.” Watch here!
Simon is the architect responsible for Project Cortex at Mott MacDonald. Mott MacDonald is one of a small number of organisations that have been involved in the development of the product prior to its subsequent Preview and General Availability releases. This has afforded Simon a unique insight into how the product can be used to enhance knowledge management.
During his recent webinar, Simon answered a variety of Project Cortex-related questions from the audience. In this post, he’s compiled all of those questions and fleshed out his answers even further. Without further ado, let’s get into the Q&A!
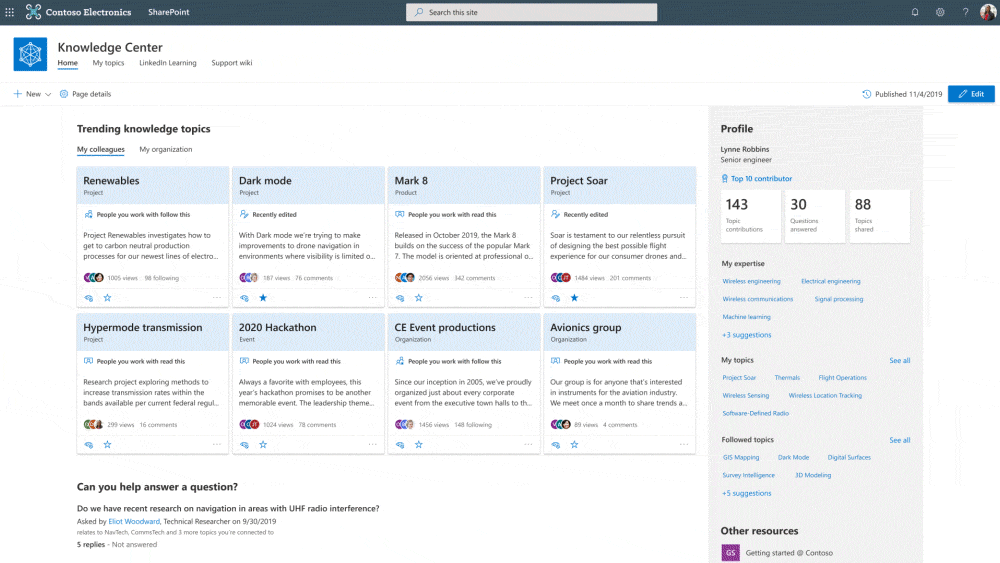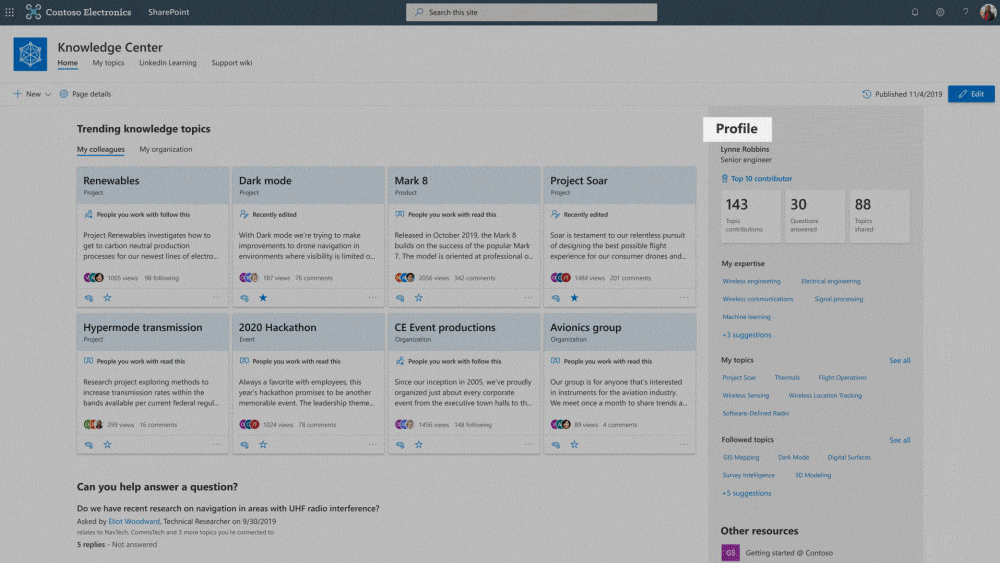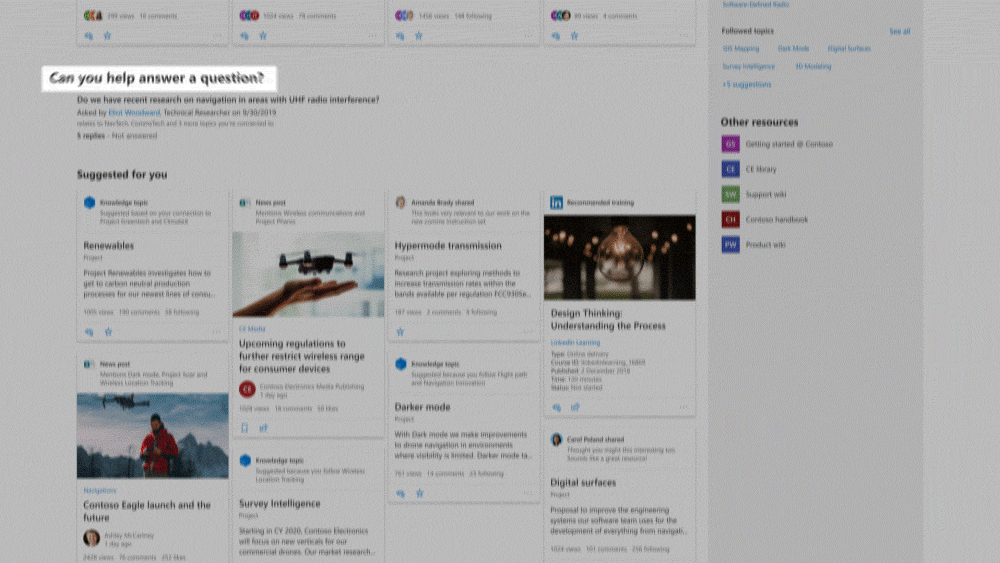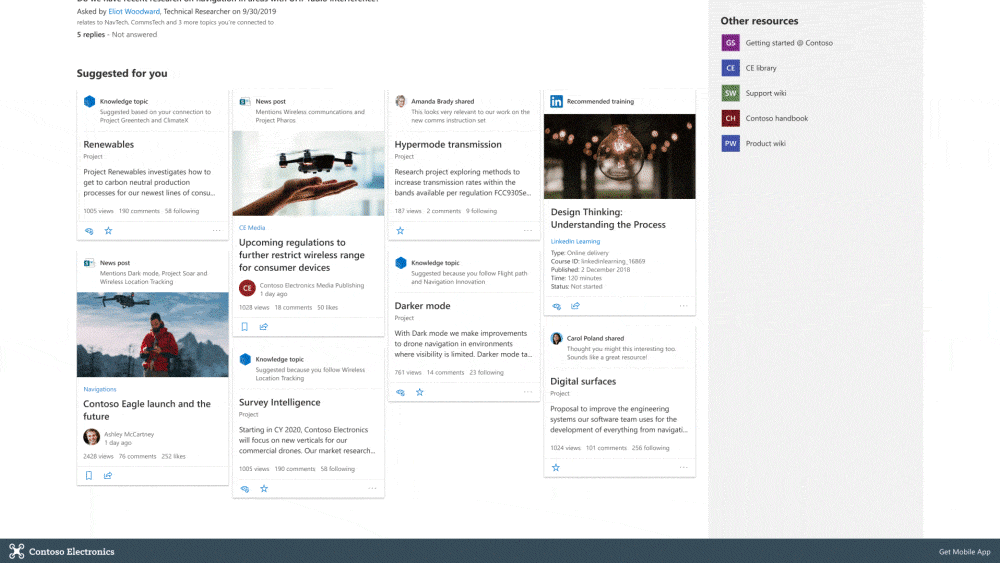
Are the keywords/taxonomy automatically created from content, or could they be seeded into Project Cortex?
Topics are automatically created by Project Cortex through Knowledge Mining. They are curated using a new feature in SharePoint called a Knowledge Centre. For the processing of specific items of structured and unstructured content, however, you can seed and train through different approaches.
One such approach is machine teaching; this lets you teach Cortex to recognize specific types of documents and associate them with particular terms. The terms are stored within the SharePoint Term Store and teaching ID performed using a Content Centre.
What kind of effort does it require upfront to teach/seed Cortex taxonomy in order to make topic cards as relevant as possible?
Not much at all; you just have to give it some representative sets of information to look at. With traditional approaches, you’d have to feed it documents in the thousands to train it, but a machine teaching platform and features like the Knowledge Centre helps to reduce this significantly. It has been our experience that we can teach it and have it understand various topics quite quickly.
Does Cortex use existing taxonomies in the initial mining exercise?
No, it uses its own. It creates its own taxonomy. Your curation process will then need to start matching those terms between the ones you have and the ones it’s come up with, and you’ll have to work out which ones are the dominant terms/topics.
What can we do now to prepare for Project Cortex’s arrival?
First, you want to get content into Office 365; you can’t benefit from Project Cortex unless the content is actually there. That could mean anything from migrating content from legacy systems to mapping it from legacy systems into Office 365.
Second, you want to get to modern pages since all the new Office 365 investments are going to require them. That said, it doesn’t mean that your entire site has to be modern. You should be able to get by with having a classic site with new modern pages in it or having parts of your intranet be based on modern pages.
Have questions about Project Cortex? Check out out this Q&A! Click To TweetThird, Project Cortex builds on your taxonomy and your managed metadata. You’re going to want to update, revamp, rethink, and clean up any existing managed metadata because you’re going to be investing in it in the future. Doing the cleanup can be vital for understanding the terms and what they mean to your organization.
However, keep in mind that that’s only necessary if you’ve got an existing taxonomy that you’re using. At some point, that taxonomy is going to get challenged by Cortex. So, if you don’t have one, just start by asking the questions “What does this term mean to me? Why am I using this term?”

Microsoft mentioned that Project Cortex is a premium service in English only. Do you have any news on any other language packs?
We’ve only been testing it in English. Several products in the Office 365 suite support multi-lingual, so it seems logical that they are (hopefully) developing the product for multi-language support.
Are there any examples of how Project Cortex could add value to a publishing company?
It is well worth checking out Project IDA (which is an Azure Labs project) because it shows what can be achieved using Cortex-like technology. Though Project IDA was developed independently of Project Cortex, it uses a lot of the same underpinning technology and approaches.
For instance, Project IDA has taken issues of the magazine The Atlantic and processed them all. As part of the processing it has extracted the topics and terms from the magazines with links out to the relevant articles and further reading. Another example is the JFK files. The JFK Files takes complex files including photos, handwriting, government documents, and more and then uses artificial intelligence and cognitive search methods to extract information.
How much of Cortex will we get included with existing Office 365 licenses?
I can’t share too much just yet as it is still to be determined by Microsoft, but hopefully we’ll all be pleasantly surprised!