




“Everything is going to be connected to cloud and data… All of this will be mediated by software.”
Reading this quote from Microsoft’s CEO demonstrates just exactly where technology innovation is headed, and it’s not only Microsoft that’s leading the charge in this field – in fact, it’s a space race and the cloud is the first stop. This is further amplified by the IDC prediction that “cloud services are set to remain a hotbed of activity in 2015/2016 with $118 billion in spending on the greater cloud ecosystem”.
It’s not surprising then that Amazon, Apple, Google, IBM and Microsoft – whom are seen as the titans of the technology industry – are all seeking to dominate the cloud. With all of this emphasis in moving to the cloud, what are the considerations for corporate and individual readiness?
This article will explore information management considerations that must be made, namely data discovery, classification, security, and migration – all of which should form part of every organisation’s cloud readiness assessment, before committing “all-in” to the cloud.
The cloud is here and the move to it is inevitable. Being at the helm requires planning, insight, and innovative technologies, which must be backed by industry expertise and process to ensure that information is managed appropriately.
We are not only in the information management age. We are now actually in the “someone else is managing my information” age and this is a very scary concept… or is it?
By following the steps in this article we can alleviate the concerns around “hard drives in the sky”, and ensure a safe and smooth adoption of the cloud.
Data Discovery
The first step to building corporate trust for a cloud strategy is understanding your current information, and to do so we should ask ourselves the following questions:
- Do you collect customer-sensitive or personal identifiable information (PII)?
- How much do you know about the information that is generated by individuals within your corporate environment?
- How old is the information and do we still need it?
- Where is the information?
- Is all of the information that of the organisations or that of the individuals or both?
These are just a few questions that should be asked when undertaking a cloud readiness data discovery. If you found yourself unable to answer some or all of these questions, then don’t fret – you are not alone. The inability of CTOs and CIOs to do so have given rise to the growth of the big data and analytics industry which is predicted by the IDC to reach $125 billion worldwide.
Big data has presented itself as one of the most prominent information management challenges for organisations that are embracing a cloud strategy. The journey to the cloud can be intricate and without the proper planning, solutions accelerators and expertise this could be even more daunting.
One innovative method for streamlining a big data move to the cloud would be to undertake a deep discovery of the individual file and its content within all of their source environments – understanding where information currently resides, what kind of information it is, and if it still needs to be managed.
Through this baseline discovery organisations can yield a number of benefits, including data volume reduction through deduplication of content. Reducing data volume amounts simplify cloud adoption in all the consideration streams – including migration, compliance and privacy, and ongoing management.
File type, file age, and file owner analysis can further develop the high-level insights required to formulate a cloud adoption roadmap. By eliminating non-business critical data and excluding this from the cloud migration strategy, organisations can accelerate the move and greatly reduce associated costs.
Classification
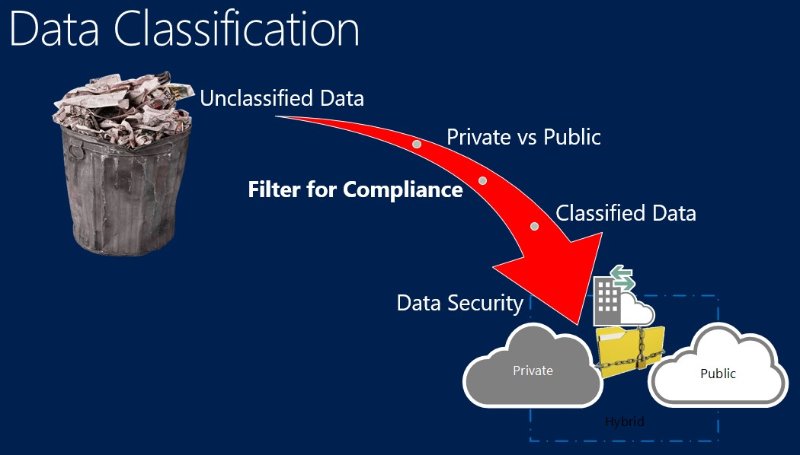
Innovations in the classification of content has culminated in providing organisations with the ability to gain content level insights of information in all of their exiting source systems. Classification technology now lets organisations create business rules for common information types. For example, a financial services organisation is responsible for maintaining credit card information (PCI) and ensuring that this information is adequately protected and maintained by their systems. For these financial services organisations a set of PCI related rules can be configured to scan the content of every file within their environment.
Also, once PCI information has been identified, automated actions can be applied based on the information that has been found – including automated deletion, redaction, permissions assignment, relocation, encryption, and quarantine. Rich discovery reporting provides the information managers with a dashboard view of scan results and what corresponding action has been performed based on the business rule defined for that content.
Migration

So far in this article we have looked at all of the pre- checks required to successfully launch an organisation into the cloud. But how do these checks enable a successful journey? Through file discovery and data analysis, organisations are able to reduce data volumes. Less data means less to actually migrate. File analysis and discovery can also help organisations understand what information should be targeted for the cloud and what should be maintained on-premises. Through real-time compliance filters, organisations can automatically scan, classify, secure, and selectively migrate content to their cloud platform.
Migration technologies that can identify existing data classification on content within existing source systems can accelerate the migration process by automatically restructuring the organisation’s Information Architecture (IA) in real-time while executing the actual migration.
It is now more important than ever to ensure that the right mix of process, expertise, and technology is considered so that an organisation has an end-to-end cloud readiness strategy to accelerate their avenue to the cloud. Cloud processing blocks can now also be leveraged to support migration technologies by allowing organisations to quickly scale-up their ‘Migration Factories’ for the duration of a migration to meet any given timeframe and decommission these on completion of the migration.
The most important consideration is to ensure that your data discovery, classification, security, and migration technologies work seamlessly together, as this will provide the ability to fully automate the entire process.
To learn about AvePoint’s solutions for data discovery and data classification, visit our website.