

Si vous avez suivi l’actualité du monde de Microsoft 365, vous avez certainement vu des annonces concernant le projet Cortex. Une annonce a tout d’abord été faite en novembre 2019 sur « [l’application de] l’intelligence artificielle (IA) avancée pour transmettre aux gens les connaissances et l’expertise nécessaires dans les applications qu’ils utilisent tous les jours ». En d’autres termes, Microsoft investit dans la gestion de connaissances de nouvelle génération afin de rassembler les données, les informations et les enregistrements sur Microsoft 365 pour qu’ils puissent être accédés, partagés et, avant tout, utilisés.
Découvrez comment sécuriser vos données grâce à notre webinaire gratuit « Protection de données sensibles dans Office 365 aux niveaux des équipes et des données. »
En savoir plus :
- Les conceptions de sites et scripts de site SharePoint
- Sécurité et conformité dans Microsoft Teams : ce qui va changer
- SharePoint et Microsoft Teams : pourquoi ils fonctionnent mieux ensemble
- Elaborez des solutions de collaboration modernes à l’aide de Microsoft Teams et de SharePoint
Partout, les gestionnaires de documents d’archive commencent à approfondir le véritable potentiel de cette automatisation avancée pour le secteur. Comment peut-on l’utiliser au mieux et que devons-nous mettre en place pour tirer parti de ces technologies nouvelles et passionnantes qui nous sont proposées ?
En termes d’application pratique, le projet Cortex a déjà lancé son premier produit : SharePoint Syntex. SharePoint Syntex est actuellement disponible pour les entreprises clientes de Microsoft 365 et peut être activé dès maintenant au sein de votre entité.
SharePoint Syntex est passionnant, car il permet aux experts commerciaux de former la solution pour qu’elle comprenne du contenu aussi bien qu’eux. Prenons l’exemple de ce que nous pourrions faire dans un contexte de gestion de documents d’archive.
Utilisation de SharePoint Syntex
Supposons que votre planning de conservation indique que vous devez conserver vos factures pendant sept ans et les bordereaux d’expédition pendant trois ans. Ou que vous devez conserver un formulaire de déclaration d’accident pendant 15 ans, mais un plan de réadaptation pendant cinq ans. Pour nous assurer que ces factures ont été classées et rattachées à la bonne classe d’élimination, il faudrait que nous fassions quelque chose comme indiquer l’endroit où les factures et les bordereaux d’expédition sont enregistrés ou demander à nos utilisateurs de les classer eux-mêmes à mesure qu’ils les enregistrent. Pour résumer, il faudrait casser l’architecture d’information ou capturer des métadonnées supplémentaires, et aucune de ces solutions n’est optimale.
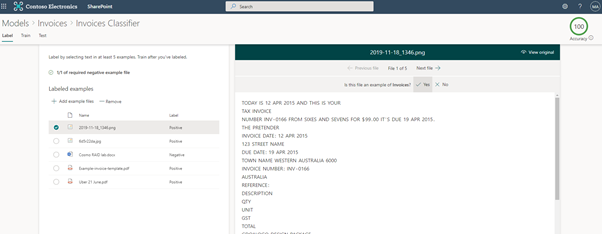
Ce que nous voulons pouvoir faire, c’est disposer d’une architecture d’information flexible sans charge pour l’utilisateur final. Des classifieurs avancés pouvant être formés, comme SharePoint Syntex, nous le permettent. Nous pouvons apprendre à SharePoint Syntex à identifier en toute confiance une facture ou un bordereau d’expédition, une déclaration d’accident ou un plan de réadaptation. Une fois que SharePoint Syntex reconnaît le contenu selon la manière dont nous l’avons formé, il classifie ce contenu en le définissant comme un type de contenu défini, par exemple une déclaration d’accident ou un plan de réadaptation. Vous pouvez également extraire des métadonnées supplémentaires à joindre au type de contenu en tant que colonnes.
Vous pouvez ensuite étendre votre programme de gestion de documents d’archive par AvePoint Cloud Records. Cette solution vous permet d’élaborer des règles pour le cycle de vie ou la conservation et l’élimination des informations tout en s’appuyant sur la technologie que Syntex propose. Comme les règles dans Cloud Records peuvent reposer sur des types de contenu et d’autres champs de métadonnées, elle peut prendre les résultats fournis par Syntex et attribuer automatiquement la bonne classification des documents d’archive et les résultats de conservation/élimination associés.
En ce qui concerne la conception globale, les capacités de SharePoint Syntex pourraient se traduire par une pression moindre sur votre architecture d’information et, tout particulièrement, par une pression moindre sur vos utilisateurs finaux. Ils bénéficieront effectivement des avantages de bonnes métadonnées sans devoir les appliquer manuellement.
Bien que ces moteurs d’intelligence automatisée avancés soient des innovations incroyables pouvant être utilisées de manière très avantageuse dans le monde des gestionnaires de documents d’archive, ils ne sont malheureusement pas encore la solution miracle de gestion de documents d’archive que nous aimerions tous désespérément avoir.
Ces outils avancés doivent encore apprendre ce que vous attendez d’eux. Je pourrais, par exemple, demander à un moteur de recherche de me montrer une image d’aliments. Ce moteur de recherche me montrera ensuite une grande variété de différents types d’aliments. Il y aura des millions et des millions d’images. Le moteur de recherche ne pouvait pas savoir que je voulais qu’il me montre l’image d’un fromage cheddar vieilli (mmmm du fromage) parce que ma demande initiale était trop générale. Nous devons toujours préciser ce que nous souhaitons obtenir et devons savoir comment y parvenir.

3 Conseils utiles
Si vous songez à SharePoint Syntex et réfléchissez à son utilité dans votre entreprise, voici trois éléments à retenir :
- Commencez à petite échelle. Prenez un sous-groupe d’informations qui se prêtent elles-mêmes à l’auto-classification (c’est-à-dire les choses que la machine peut facilement trouver à répéter, les modèles, etc.), puis pensez au résultat que vous souhaitez obtenir. Commencer à petite et simple échelle vous permettra de tester ce qui fonctionne vraiment pour votre processus et votre entreprise. C’est une bonne occasion d’apprendre avant de continuer à déployer.
- Engagez-vous dans vos secteurs d’activité. C’est leur savoir que vous voulez que la machine reproduise afin qu’ils puissent se concentrer sur d’autres choses. Qu’est-ce qui leur sera le plus utile ? Qu’est-ce qui contribuera à améliorer leur vie ?
- Affiner encore et toujours. Comme toute nouvelle chose, ce ne sera pas parfait au premier essai, mais en affinant et en révisant, vous pourrez obtenir d’excellents résultats d’automatisation.
Il y a tout simplement trop de données et d’informations pour que nous, gestionnaires de documents d’archive, les supervisions comme nous le faisions auparavant. Nous devons tirer parti des outils d’automatisation qui arrivent sur le marché et peuvent nous aider à obtenir les résultats qu’il nous faut et ce, sans peser sur les utilisateurs ou la main-d’œuvre des gestionnaires de documents d’archive que nous n’avons tout simplement pas.
Il existe de nombreux moyens de soutenir les résultats de la gestion de documents d’archive par l’intelligence automatisée et le seul moyen d’en savoir plus est de s’y mettre !
Pour en savoir plus sur les subtilités de SharePoint et Microsoft Teams, abonnez-vous à notre blog !