

Mit der diesjährigen Weihnachtszeit möchte ich euch das Warten auf das Fest etwas verkürzen und jeden Tag einen spannenden Tipp zu SharePoint geben. Die Themen umfassen dabei SharePoint Performance Tuning, Performance Monitoring, Best-Practices für SP-SQL-Konfigurationen, BLOB Management und Backup & Recovery. Viel Spaß!
SharePoint Adventskalender – 1. Türchen
SharePoint Performance Tuning – Cluster Größe der SQL Festplatten
Das Kollaborationsportal SharePoint ist aus der Unternehmenswelt nicht mehr wegzudenken. In immer mehr Firmen wird es eingesetzt. Dabei soll es andere Portale oder auch die klassischen File-Shares ersetzen. Das damit verbundene Umgewöhnen von bekannten Prozessen und Abläufen ist nicht für jeden einfach. Um alle Mitarbeiter von dem Portal zu überzeugen, sollte es daher einfach zu bedienenen sein und Anfragen schnell bearbeiten.
Aber was schlägt Ihnen die Suchmaschine Ihrer Wahl als erstes vor, wenn Sie mit den Worten beginnen: „Why is SharePoint…“? Richtig, das erste Ergebnis ist: „Why is SharePoint so slow“.
Die Inhaltsdatenbanken von SharePoint müssen eine Vielzahl von Aufgaben bewältigen, wie z.B. Suche, ECM, Workflows, Collaboration (Co-Authoring) und vieles mehr. Bei schlechter Wartung können diese Operationen die Performance enorm beeinflussen. Vor allem auch deswegen, weil die SharePoint Inhaltsdatenbanken so entwickelt sind, dass sie ohne großes Eingreifen funktionieren – also einfach installieren und los. Leider sind aber die dabei vergebenen Standardwerte nicht optimal. Passt man diese nicht an, wird SharePoint langsam.
Die erste Stellschraube, an der Sie drehen können, ist die Cluster Größe auf den SQL Festplatten.
Sie haben Ihre SQL-Datenbanken auf einer Standard-NTFS Partition installiert und haben nun Performance Probleme? Dann könnte auch die Cluster Größe der zugrundeliegenden Speicherpartition eine Ursache sein. Wussten Sie nämlich, dass die standardmäßige Cluster Größe bei der Erstellung eines NTFS Laufwerks bei 4KB liegt? Dies ist ein schönes Beispiel für Standardwerte, die leider für unseren SQL nicht gut funktionieren.
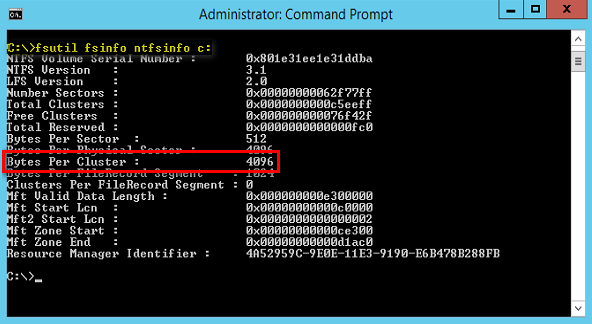
SQL bevorzugt nämlich eine Cluster Größe von 64KB. Dies ist darauf zurückzuführen, wie SQL seinen Speicher innerhalb seiner Datendateien (MDF oder NDF) verwaltet. Dazu wird dieser logisch in 8KB große Seiten (Pages) unterteilt. Dies ist die grundlegende Einheit für die Datenspeicherung im SQL. Für eine effizientere Speicherverwaltung werden zudem immer acht physisch zusammenhängende Seiten zu Blöcken (Extents) zusammengefasst. Die Rechnung ist also einfach: 8 Seiten x 8KB = 64KB.
Wenn Sie also Performance-Probleme haben, denken Sie darüber nach, Ihre Datenbankdateien auf Laufwerke mit 64KB Cluster Größe zu verschieben. Selbst mit einer VM innerhalb der IaaS Lösung von Microsoft Azure ist durch diese Cluster Größe eine 20% bessere Festplatten-Performance zu messen. Auch diese Möglichkeit sollten Sie also berücksichtigen, wenn Sie ihre SharePoint Performance verbessern möchte.
SharePoint Adventskalender – 2. Türchen
SharePoint Performance Tuning – SQL Speicherzuweisung
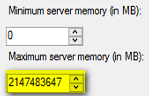 Kommt Ihnen die Zahl 2147483647 bekannt vor? Dies ist der Speicherwert in MB, der SQL maximal vom Arbeitsspeicher zur Verfügung steht – also 2 PB (PetaByte!).
Kommt Ihnen die Zahl 2147483647 bekannt vor? Dies ist der Speicherwert in MB, der SQL maximal vom Arbeitsspeicher zur Verfügung steht – also 2 PB (PetaByte!).
Der SQL nimmt sich so viel Arbeitsspeicher, wie er braucht und wie er kriegen kann. Dabei ist es SQL egal, ob dem Betriebssystem noch etwas übrig bleibt. Hat SQL einmal so viel Arbeitsspeicher genommen, dass selbst das Betriebssystem keine weiteren Prozesse und Threads bearbeiten kann, so hängt der Server. Die CPU Nutzung und Disk I/O erhöhen sich stark, weil Windows beginnt, mehr und mehr RAM auf die Festplatte auszulagern. Dadurch erhöhen sich die Antwortzeiten und SharePoint wird langsam, bzw. fällt ganz aus, wenn die Datenbankserver neu gestartet werden müssen, um das Problem zu lösen.
Daher sollte man den maximalen Wert der Arbeitsspeicherzuteilung so einstellen, dass stets ein Rest für das Betriebssystem bleibt. Bei kleineren Servern sind etwa 80-85% des maximal verfügbaren Speichers zu empfehlen. Bei sehr viel verfügbarem Speicher (> 64 GB) sollte etwa 8 GB für das Betriebssystem reserviert werden. Bitte denken Sie auch daran, sollten bei Ihnen mehrere SQL Instanzen auf einem Server laufen, dass sich natürlich die zugewiesenen Speicher pro Instanz addieren. Also bei beispielsweise zwei Instanzen sollten beide zusammen nicht die 80-85% überschreiten, bzw. bei größeren Systemen 8 GB übrig lassen.
Auch wenn der minimale Wert keine großen Probleme macht, so empfehle ich, diesen auf 1-2 MB zu setzen, damit SQL immer eine Grundlast hat. SQL läuft damit stabiler und ist schnell auf „Betriebstemperatur“.
SharePoint Adventskalender – 3. Türchen
SharePoint Performance Tuning – SQL MAXDOP
Sicherlich sollte diese Einstellung jedem SharePoint Administrator bekannt sein. In SharePoint 2013 gibt es sogar eine Health Analyzer Regel, die den gesetzten Wert des Maximalen Grad an Parallelität (MaxDegreeOfParallelism) überprüft. Ich möchte dennoch erklären, was genau dahinter steckt und warum dieser Wert so wichtig für die SharePoint Performance ist.
Die MAXDOP kann beschränken, wie viele Prozessorkerne SQL gleichzeitig nutzen soll, um Anfragen abzuarbeiten. Also je mehr Kerne, desto schneller kann SQL arbeiten. Dies funktioniert auch sehr gut, wenn es um reine Datenbankaufgaben geht, weil SQL sehr intelligent die Anfragen verteilt.
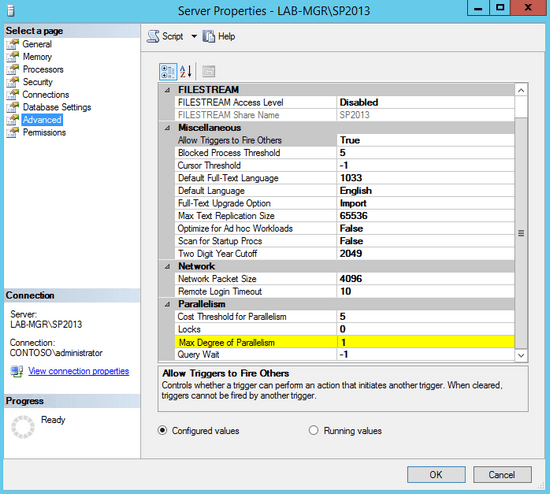
Kompliziert wird es nur, wenn SharePoint ins Spiel kommt. Denn SharePoint optimiert die Anfragen, bevor sie tatsächlich an den SQL gesendet werden. Das heißt, der erneute Versuch seitens SQL, die eingehenden Anfragen zu optimieren, lässt das ganze ineffizient werden. Daher sollte der Wert auf 1 gesetzt werden, damit die Anfragen so abgearbeitet werden, wie sie vom SharePoint kommen.
Zur Information: Der Wert 0 (standard), nutzt alle verfügbaren Prozessorkerne. Die Werte 2 bis n adressieren die genaue Anzahl der Kerne, die genutzt werden sollen. Setzen können Sie den Wert pro Instanz in den Instanzeinstellungen. Navigieren Sie dort zu den erweiterten (Advanced) Einstellungen.
SharePoint Adventskalender – 4. Türchen
SharePoint Performance Tuning – SQL AutoGrowth-Einstellungen
Auch bei den AutoGrowth-Einstellungen sind die SQL Standardwerte leider alles andere als optimal gewählt. Aufgrund einer kleinen Startgröße und kleiner automatischer Vergrößerungsschritte, können Daten nicht fortlaufend in die Blöcke (Extents) und Seiten (Pages) geschrieben werden. Dies geschieht bei allen INSERT-, UPDATE- und DELETE-Vorgängen. Es kommt zur Fragmentierung, die zu einer schlechteren Performance führt.
Weiterhin werden bei jedem AutoGrowth-Vorgang Server-Ressourcen verbraucht. Bei prozentualen Änderungen kommen noch Kalkulationsvorgänge hinzu. Dies sind alles zusätzliche Operationen, die der SQL nebenbei ausführen muss, bevor er die eigentlichen SharePoint-Anfragen abarbeiten kann. Wir erkennen also, dass wir mit den AutoGrowth-Einstellungen viel beeinflussen können.
Häufige AutoGrowth-Operationen fragmentieren außerdem in Hohem Maße das Transaction-Log. Wie können wir uns das vorstellen? Intern ist jedes Transaction-Log in kleinere virtuelle Logs unterteilt (Virtual Log File – VLF). Abhängig von der Größe, um die das Log erweitert werden soll, wird dieser “Chunk” in unterschiedlich viele virtuelle Logs aufgeteilt. Dies geschieht nach folgender Regel:
- Chunks bis 64MB = 4 VLFs
- Chunks mehr als 64MB und bis zu 1GB = 8 VLFs
- Chunks mehr als 1GB = 16 VLFs
Aber: Ab SQL 2014 wurde diese Regel etwas angepasst. Ist die Chunk-Größe kleiner als 1/8 der aktuellen Log-Größe?
- Ja: Erstelle eine neue VLF in der Größe des Chunks
- Nein: Nutze die Formel oben
Bei vielen kleinen AutoGrowth Operationen mit noch kleinere virtuellen Logs (besonders bevor SQL 2014) fragmentiere ich also meine Datenbanken und Logfiles extrem – und dies beeinflusst die Performance.
Wir gehen noch weiter ins Detail: Angenommen, wir haben eine Datenbank von initial 80 MB und ein ebenso großes Log. Nach obiger Regel haben wir also 8 etwa gleich große virtuelle Log Dateien zu je 10 MB. Nun laden wir in SharePoint eine 12 MB Datei hoch. Was passiert?

SQL “schaut” in jedes virtuelle Log, ob die Datei da rein passt. Wenn nicht, versucht SQL das nächste usw. Wurden alle VLFs probiert, ohne die Datei schreiben zu können, so wird erst danach eine entsprechende AutoGrowth-Operation durchgeführt, um die Operation abschließen zu können. In der Ziwschenzeit sind aber bereits 8 I/Ops für die Versuche vergangen, die Datei in die kleineren VLFs zu schreiben. Und nun stellen Sie sich vor, sie haben extrem viele dieser kleineren VLFs. Die Summer der nötigen I/Ops dürfen Sie sich gern selber ausrechnen…
Mit der einfachen Query “DBCC LOGINFO” auf die jeweilige Datenbank können Sie herausfinden, wie viele virtuelle Log-Dateien Sie haben. Die ausgegebene Anzahl der Zeilen, entspricht der VLFs. Sollten es mehr als 50 sein, empfehle ich, diese zu bereinigen und die inkrementellen Zuwachsraten (AutoGrowth) anzupassen. (Weitere Details zur Log Datei Bereinigung finden Sie hier: http://www.sqlskills.com/blogs/kimberly/8-steps-to-better-transaction-log-throughput/)
Die Zuwachsraten sollten idealerweise einen festen und keinen prozentualen Wert haben. Der Wert der Vergrößerung sollte etwa 10 % der Datenbankgröße betragen. Bei einer Inhaltsdatenbank von 10 GB wäre somit der Autozuwachs auf 1 GB einzustellen. (Soll die Datenbank 100 GB und größer werden, können auch größere Zuwachsschritte gewählt werden.) Für die Log-Datei sollte dies ähnlich konfiguriert werden.
Als Ergebnis werden wir weniger Vergrößerungsoperationen haben, welche die Serverleistung reduzieren. Weiterhin haben wir eine geringere Fragmentierung, sodass SharePoint-Anfragen schneller bearbeitet werden können.
——————————————–
Danke auch an Paul Randal http://www.sqlskills.com/blogs/paul/important-change-vlf-creation-algorithm-sql-server-2014/
SharePoint Adventskalender – 5. Türchen
SharePoint Performance Tuning – SQL Datenbanken vor konfigurieren
Heute nur eine schnelle und kurze Information in Anlehnung an den gestrigen Beitrag (http://blogs.msdn.com/b/robert_mulsow/archive/2015/12/04/sharepoint-performance-tuning-sql-autogrowth-einstellungen.aspx).
In Bezug auf die AutoGrowth-Einstellungen ist es fast schon logisch, dass idealerweise die Datenbanken (durch Datenbankadministratoren) für die SharePoint-Installation vor konfiguriert werden. So vermeiden wir schon bei der Installation und Anbindung die ersten Autogrowth-Operationen.
Die Initialgrößen sollten dabei ausreichend groß gewählt werden, in Hinblick auf die zu erwartende Größe der Inhaltsdatenbanken. Dies muss aber noch nicht die von Microsoft empfohlene Maximalgröße sein. Denn eine initial große Datenbankdatei würde natürlich auch die Backup-Größe und -Zeit beeinflussen. Ein paar Wochen sollten die Datenbanken aber ab Ihrer Erstellung ohne Vergrößerung auskommen. Nach Erreichen der konfigurierten Initialgröße beginnt dann der erste Autogrowth.
SharePoint Adventskalender – 6. Türchen
SharePoint Performance Tuning – SQL TempDB Einstellungen
Die TempDB des SQLs kann man im weitesten Sinne wie den RAM-Speicher des Betriebssystems verstehen. Sie speichert unter anderem temporäre Benutzerobjekte wie Tabellen und Prozeduren, interne Objekte z.B. für das Speichern von Zwischenergebnissen und Zeilenversionen zum Beispiel für Datenänderungstransaktionen. Die TempDB wird bei jedem Start von SQL neu erstellt und alle gespeicherten Daten werden beim Trennen der SQL-Verbindung wieder gelöscht.
Mit dieser Analogie zum RAM-Speicher ist also leicht zu verstehen, dass Optimierungen der TempDB auch zur Verbesserung des gesamten SQLs führen und damit auch unseren SharePoint beschleunigen. Die verschiedenen Möglichkeiten, um die TempDBs zu optimieren, möchte ich hier auflisten:
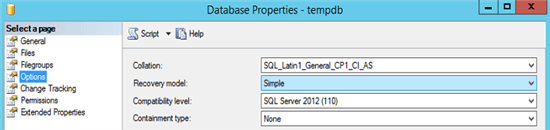
- Das Recovery Model sollte auf SIMPLE gestellt werden
- Die TempDB kann auf mehrere Dateien aufgeteilt werden
- bei bis zu acht logischen Prozessoren: #Kerne = #TempDB-Dateien
- bei mehr als acht Prozessoren genau acht TempDB-Dateien konfigurieren
- wenn Speicherkonflikte (In-Memory-Contentions) auftreten, sollten die TempDB-Dateien jeweils um vier erweitert werden, bis die Konflikte auf ein normales Niveau absinken
- Hinweis: Daumenregel besagt #Kerne = ½ bis ¼ TempDB-Dateien
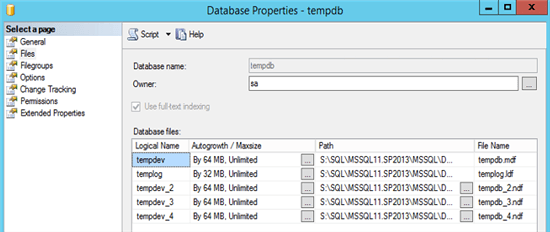
- alle TempDB-Dateien sollten die gleiche Größe und gleichen Einstellungen haben
- jede Datei sollte 25 % der Größe der größten Inhaltsdatenbank haben
- die Dateien können auch über mehrere Spindeln verteilt werden, um eine noch bessere Performance zu erzielen
- Hinweis: Da alle zusätzlichen Datendateien per Definition SECONDARY-Dateien sind, sollten Sie das Format *.ndf zuweisen anstelle des *.mdf für die initiale PRIMARY-Datei.
- Die TempDBs sollten auf den schnellsten Laufwerken platziert werden
- Auf den TempDB-Laufwerken sollte mehr als 25 % freier Speicher zur Verfügung stehen, um zu Peak-Zeiten das Anwachsen der Dateien zu ermöglichen
- AutoGrowth ähnlich konfigurieren wie für Inhaltsdatenbanken, siehe 4. Türchen (Link unten)
Das sind einige Punkte, die Sie berherzigen sollten. Gleichzeitig macht dies auch deutlich, wie viele nicht optimale SQL Einstellungen es gibt, wenn unser SharePoint mit ins Spiel kommt. Aber schlechte Gewissen, ob Ihre Datenbanken optimal für SharePoint konfiguriert sind, soll es heute nicht geben. Genießen Sie stattdessen den Nikolaus und den 2. Advent. Aber schauen Sie gleich morgen mal nach bzw. sprechen Sie mit Ihren SQL-Admins.
Viel Spaß beim “SharePointen”!