

Mit der diesjährigen Weihnachtszeit möchte ich euch das Warten auf das Fest etwas verkürzen und jeden Tag einen spannenden Tipp zu SharePoint geben. Die Themen umfassen dabei SharePoint Performance Tuning, Performance Monitoring, Best-Practices für SP-SQL-Konfigurationen, BLOB Management und Backup & Recovery. Viel Spaß!
SharePoint Adventskalender – 7. Türchen
SharePoint Performance Tuning – Der Papierkorb
Performance Tuning – Performance Monitoring – Best-Practices für SP-SQL-Konfigurationen – BLOB Management – Backup & Recovery
Oft unterschätztes, aber dennoch wichtiges Element beim SharePoint Performance Tuning ist der Papierkorb. Bei vielen Unternehmen wird dieser sogar in die Backup-Strategie mit einbezogen. Grundsätzlich ist das möglich, aber nicht optimal. Warum? Das möchte ich erklären.
Sobald man Objekte in den Papierkorb verschiebt, bleiben sie immer noch in der SharePoint Inhaltsdatenbank, damit Endnutzer sie notfalls schnell wieder herstellen können. Oft vergessen wird aber, dass ein Objekt beim Löschen, also beim Verschieben in den Papierkorb, bereits einige seiner Metadaten verliert. Genauer möchte ich darauf jedoch erst im Rahmen der Backup-Best-Practices in einem der späteren Adventskalender-Türchen eingehen.
In Hinblick auf die Performance haben Sie den kleinen Hinweis aber vielleicht schon richtig erkannt: Auch Daten im Papierkorb sind Daten, die weiterhin in der Inhaltsdatenbank liegen! Je größer die Datenbanken, desto länger dauern die Queries, bis sie durch die Datenbank-Tabellen gelaufen sind. Bei stark belasteten Instanzen kann sich so ein Unterschied von mehreren GB schon bemerkbar machen. Sicherlich sprechen wir hier nicht von Sekunden, die den Unterschied je Query ausmachen, aber es ist dennoch ein wichtiger Baustein eines optimalen Performance Tunings für SharePoint.
Achten Sie daher darauf, welche Einstellungen Sie für die Aufbewahrung in Papierkörben wählen. Idealerweise so kurz wie möglich und nutzen Sie stattdessen eine bessere Backup-Strategie mit Drittanbieterlösungen.
Viel Spaß beim „SharePointen“!
SharePoint Adventskalender – 8. Türchen
SharePoint Performance Tuning – Warm Up Skripte
Performance Tuning – Performance Monitoring – Best-Practices für SP-SQL-Konfigurationen – BLOB Management – Backup & Recovery
Lange Zeit hat Microsoft behaupted, SharePoint ist so gut programmiert, dass es immer laufen wird und man noch nicht einmal Application Pool Recycles (Neustart eines Application Pools) benötigt. In der Realität sieht das ganze natürlich anders aus, wie wir alle wissen. Daher sollte man für die SharePoint Application Pools die regelmäßigen Neustarts – standardmäßig jede Nacht – vom IIS durchführen lassen.
So ein App Pool Neustart sorgt dafür, dass der Worker-Prozess, der die Anfragen des Pools bearbeitet, gestoppt und neu gestartet wird. Dies ist notwendig, um mögliche Abstürze, hängende Anfragen oder RAM-Speicherprobleme zu vermeiden.
Der Nachteil an diesem Verfahren ist, dass danach auch alle zwischengespeicherten Informationen (Cache) verloren sind und diese nun bei jedem neuen Seitenaufruf neu gezogen werden müssen. Also ist in diesem Fall der „frühe Vogel“ morgens im Büro unser „Warmup Skript“, dass wieder alle SharePoint-Seiten in den Cache lädt.
Die möglichen Beschwerden eines langsamen SharePoints unserer „frühen Vögel“ können die IT-Administratoren jedoch vermeiden, indem sie ein automatisches WarmUp Skript laufen lassen. Exemplarisch möchte ich das SPBestWarmUp Skript von der Codeplex Platform nennen (https://spbestwarmup.codeplex.com/), da ich es selber auch verwende. Es gibt aber noch viele weitere Skripte, die ihr persönliches Szenario besser oder schlechter abdecken können.
Idealerweise sollten solche Skripte aber automatisch die Seiten für einen Aufruf im Hintergrund erkennen, damit sie im Application Pool Cache landen. Sehr schön sind auch zusätzliche Optionen wie z.B., dass weitere URLs händisch hinzugefügt werden können oder der Fortschritt und mögliche Probleme auch geloggt werden können. In diesem Falle haben Sie als Administartor gleich morgens pro-aktiv einen Fall auf dem Tisch, sollte mal eine Seite sich nicht mehr öffnen lassen, weil vielleicht ein sogenannter „Power User“ mit einem JavaScript den Seitenaufruf blockiert.
Wichtig ist daher, dass Sie diese Skripte in den Windows Task Scheduler laden oder in einer anderen Form automatisch nach einem Application Pool Recycle starten lassen, um einem langsam SharePoint am morgen auf die Sprünge zu helfen.

Probieren Sie es aus!
SharePoint Adventskalender – 9. Türchen
SharePoint Performance Monitoring – Performance Counter für den Prozessor
Performance Tuning – Performance Monitoring – Best-Practices für SP-SQL-Konfigurationen – BLOB Management – Backup & Recovery
Nachdem wir nun eine Menge für die Performance getan haben und unser SharePoint jetzt „rennt“ wie nie zuvor, wollen wir auch dafür sorgen, dass es dabei bleibt. Dazu müssen wir die Performance mit geeigneten Indikatoren überwachen. Die Auswahl der richtigen Messgrößen ist dabei sehr wichtig, weil jede Plattform, System oder Applikation die verschiedenen Parameter der zugrundeliegenden Hardware unterschiedlich belastet. Überwache ich beispielsweise die Prozessorauslastung für eine Applikation, die hauptsächlich über den RAM Speicher arbeitet, dann „monitore“ ich am Ziel vorbei.
Heute und in den nächsten Tagen möchte ich daher Performance Counter aus dem Microsoft Windows Performance Monitor vorstellen, die Messgrößen überwachen, welche besonders wichtig für einen schnellen SharePoint sind. Den Anfang sollen dafür die CPU-Counter machen.
Prozessorprobleme treten auf, wenn die CPU voll ausgelastet ist und daher Anfragen nicht schnell oder sogar gar nicht mehr abgearbeitet werden können. Eine hohe Prozessoraktivität ist dazu zwar ein erstes Indiz, aber beispielsweise eine dauerhaft lange „Warteschlange“ für Prozessoranfragen (12. Türchen) ist noch aussagekräftiger.
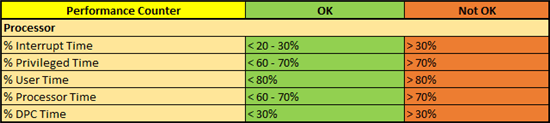
% Interrupt Time
Dieser Indikator gibt an, wie viel Prozent die CPU ihrer Zeit für Prozessunterbrechungen verliert. So kann beispielsweise eine alte Netzwerkkarte auf einem sehr stark ausgelastetem IIS Server (SharePoint Web Front End) diesen Wert nach oben treiben. Aber grundsätzlich auch fehlerhafte Hardware kann den Wert nach oben bringen. Generell sollte dieser Wert nicht dauerhaft 30% übersteigen. Andernfalls sollten sie herausfinden, was die Ursache dafür ist, da es die SharePoint Performance negativ beeinflusst.
% Privileged Time
Gewöhnlich sollte der Prozessor seine Operationen im User Mode (siehe unten) ausführen, da dieser für Applikationen, Teilsysteme und integrierte Teilsysteme gedacht ist. Der „Privileged“ oder auch „Kernel“ Mode hingegen ermöglicht den Zugriff auf system-spezifische Operationen, wie z.B. Gerätetreiber-Aufrufe oder Deferred Procedure Calls (DPC siehe unten). Diese speziellen Aktionen können im schlimmsten Fall auch das gesamte System zum Absturz bringen. Ein zeitlich hoher prozentualer Anteil an diesen Kernel-Mode Operationen (>30%) deuten auf schlechte Gerätetreiber oder fehlerhafte Hardware hin. Dies allein ist schon nicht optimal, aber im Hinblick auf unsere Performance bleibt so weniger Zeit, um SharePoint-Operationen im User-Mode ausführen zu können.
% User Time
Die abgearbeiteten Threads im User Mode sind hingegen in einer sicheren „Einheit“ und können nicht andere Programme und Applikationen beeinflussen. Dies ist ein ähnlicher Ansatz, wie wir es aus SharePoint 2010 mit den Sandbox Solutions kennen. Die User Time für sich sagt noch nicht so viel aus. Interessanter wird es, wenn wir es in Kombination mit der Privilege Time vergleichen. Viel Privilege und wenig User kann auf obige Probleme hindeuten. Wenig Privilege und viel User ist zunächst in Ordnung. Wird die User Time aber besonders groß, kann dies auch darauf hindeuten, dass Sie schlecht oder fehlerhaft programmierte Anpassungen wie JaveScripts oder ähnliches in Ihrem SharePoint laufen haben. Achten Sie daher darauf, dass die Werte für diesen Indikator nicht 70% übersteigen.
% Processor Time
Dieser Indikator ist der Hauptindikator für die Prozessoraktivität und gibt an, welchen Teil seiner Zeit der Prozessor damit beschäftigt war, Threads abzuarbeiten. Dieser Wert wird nicht direkt gemessen. Stattdessen wird die Leerlaufzeit gemessen, also das Warten, bis ein nächster Thread fertig ist, abgearbeitet zu werden. Zieht man nun die prozentuale Leerlaufzeit von 100% ab, erhalten wir die % Processor Time. Grundsätzlich ist eine Auslastung von mehr als 70% nicht optimal und würde daher seinen Anteil zu einer schlechten SharePoint Performance beitragen.
Noch ein Hinweis zur Zeitmessung: Dies ist ein internes Standardintervall von 10 ms. Besonders neuere Prozessoren arbeiten sehr schnell. Zum Messpunkt können Sie zwar kurzzeitig im Leerlauf sein, aber sie haben vielleicht trotzdem innerhalb des Zeitintervall Threads abgearbeitet. Das Intervall wird dennoch ganzheitlich als Leerlauf in die Brechnung aufgenommen und daher kann die Prozessorauslastung geringer ausfallen, als sie tatsächlich ist.
% DPC Time
Ein Deferred Procedure Call ist eine Operation im Privilege Mode (siehe oben), jedoch mit geringer Priorität. Er wird ausgelöst, wenn z.B. ein Hardware-Gerät den Prozessor unterbricht und der „Interrupt Handler“ entscheidet, dass noch offene und notwendige aber weniger wichtige Operationen erst später ausgeführt werden. So kann z.B. verhindert werden, dass schlechte Gerätetreiber mit weniger wichtigen Operationen, nicht andere wirklich kritische Aktionen blockieren. Die prozentuale DPC Time ist also ein zusätzlicher Indikator für die prozentuale Interrupt Time und bestätigt, ob schlechte Hardware und deren Treiber viele unwichtige Unterbrechungen und Operationen ausführen möchten und damit die Abarbeitung von User Mode Aktionen blockieren. Da eine dauerhafte % DPC Time über 30% nicht optimal ist, sollten Sie also auch diesen Indikator ernst nehmen.
Für alle Counter gilt, dass sie mit einem Account ausgeführt werden müssen, der über die notwendigen berechtigungen verfügt, um die Daten sammeln zu können, wie z.B. Nutzer der Gruppe Performance Monitor Users. Zudem können Sie die Indokatoren auch ganz gezielt für einzelne Prozessor(-kerne) konfigurieren, um beispielsweise im Problemfall noch gezielter die Ursache zu finden. Achten Sie also darauf, wenn Sie sich ein Collector Set konfigurieren, dass Sie nicht die Werte über alle Kerne messen (_Totel), wie in meinem Screenshots unten, sondern selektieren Sie die Kerne 1 bis n einzelnd.
Viel Spaß beim „SharePointen“!
SharePoint Adventskalender – 10. Türchen
SharePoint Performance Monitoring – Performance Counter für Speicherlaufwerke
Performance Tuning – Performance Monitoring – Best-Practices für SP-SQL-Konfigurationen – BLOB Management – Backup & Recovery
Sehr häfig wird nur über die CPU und den RAM Speicher gesprochen, wenn es um Performance geht. Leider wird aber oft das Disk Sybsystem dabei vergessen, denn es hat einen erheblichen Einfluss auf die Leistungen der Systeme, die darauf laufen – ganz besonders bei SQL. Ich möchte daher heute ein paar Counter vorstellen, die Ihnen helfen, Ihre Disk-Performance im Auge zu behalten.
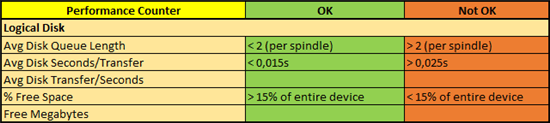
Avg Disk Queue Length
Dieser Wert gibt die durchschnittliche Anzahl der Anfragen an, die auf einen Festplattenzugriff warten. Dieser Wert beinhaltet neben den Anfragen in der „Warteschlange“ auch diejenigen, die aktuell in Bearbeitung sind. Warum ist das so? Dies liegt daran, dass dieser Indikator nicht direkt gemessen wird, sondern nach der Formel (Disk Transfers/sec) x ( Disk sec/Transfer) berechnet wird (beide Indikatoren siehe unten). Er gibt dennoch eine sehr gute erste Indikation, ob alles auf den Festplatten (also eigene oder angebundene Speicherlaufwerke) in Ordnung ist. Der Wert sollte nicht größer als 2 je Spindel sein.
Avg Disk Seconds/Transfer
Dieser Indikator misst die durchschnittliche Zeit, die vergeht, bis eine Transferabfrage abgearbeitet ist, unabhängig davon, wie viele bytes tatsächlich dabei gelesen or geschrieben werden mussten. Die Größe zeigt an, wie effizient das Disk Subsystem arbeitet. Werte größer als 0,025 Sekunden sind nicht optimal und deuten an, dass Anfragen häufig wiederholt werden müssen, weil sie entweder durch zu lang andauernde Anfragen oder eine zu lange Warteschlange fehlgeschlagen sind. In weniger häufigen Fällen deuten sie auch auf einen Plattenfehler hin.
Avg Disk Transfer/Seconds
Die durchschnittliche Anzahl an Transfers (I/Ops – Input/Output operations per second), die pro Sekunde abgeschlossen werden, hat zunächst keinen Grenzwert. Vielmehr kann sie als Richtwert betrachtet werden, wie gut (also wie viele) I/Ops Ihr Disk Subsystem pro Sekunde erfolgreich abarbeiten kann.
Als Beispiel können wir hier dennoch einen Grenzwert von Microsoft heranziehen. Für Inhaltsdatenbanken bis zu 4 TB Größe setzt Microsoft eine Plattenperformance von mindestens 0,25 I/Ops pro GB voraus (SharePoint 2013). Bei einer 4 TB Datenbanken müssen die Platten also mindestens 1024 I/Ops leisten können. Das würde ich als „sportlich“ bezeichnen.
% Free Space
Der prozentuale Anteil an freiem Speicherplatz auf den logischen und physischen Platten ist selbsterklärend. Natürlich sollte immer ausreichend Puffer vorhanden sein, damit beispielsweise nicht plötzlich Backup-Vorgänge abbrechen oder Datenbanken nicht weiter wachsen können. So einfach es klingt, sie glauben nicht, wie häufig diese Fehler bei Kunden auftreten…
Ich empfehle daher, dass Sie immer mehr als 15% der gesamten Speicherkapazität frei halten, damit Sie nicht in obige Probleme geraten. Nutzen Sie also Monitoring Werkzeuge, die Sie bei dieser Überwachung unterstützen.
Free Megabytes
Zum prozentualen Anteil an freiem Speicherplatz, sollten auch die harten Zahlen mit beobachtet werden. In einem beispielhaften Szenario hören sich nämlich 25% freier Speicher zunächst einmal entspannt an. Bedeutet dies aber nur rund 25 GB in echten Zahlen, dann sehe ich hier dringenden Handlungsbedarf – besonders wenn es sich um ein Speichersystem handelt, auf dem Farm-Backups abgelegt werden sollen. Seien Sie also wachsam.
Viel Spaß beim „SharePointen“!
SharePoint Adventskalender – 11. Türchen
SharePoint Performance Monitoring – Performance Counter für den Arbeitsspeicher
Performance Tuning – Performance Monitoring – Best-Practices für SP-SQL-Konfigurationen – BLOB Management – Backup & Recovery
Wie im gestrigen Kelander-Türchen erwähnt, reduziert man sich oft bei Performance-Diskussionen auf einzelne Komponenten. Sicherlich kann eine einzelne Einheit einen Engpass darstellen, aber es ist immer das gesamte Systems, das aufeinander abgestimmt werden muss, um bestmögliche Leistungen zu erzielen. Da der Arbeitsspeicher (RAM) in der Tat ein sehr wichtiger Teil der Hardware und damit der gesamten Infrastruktur ist, schauen wir uns heute ein paar Performance Counter an, auf die Sie achten sollten, damit der RAM nicht zum „Bottleneck“ wird.
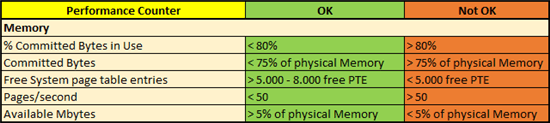
% Committed Bytes in Use
Der Arbeitsspeicher wird zusätzlich auf der Festplatte durch eine sogenannte Paging File abgebildet. Auf diese Datei wird der gesamte Inhalt des Arbeitsspeichers geschrieben, sollten wir z.B. auf Endanwender-Laptops in den Schlaf- oder Ruhemodus wechseln. Dieser Counter gibt also an, wie viel „virtueller“ Speicher aktuell vom RAM genutzt wird. Oder anders ausgedrückt, der Wert gibt uns das Verhältnis von zugesicherten Bytes zum Maximalwert der dazugehörigen Paging File an. Ist dieser Wert dauerhaft über 80%, so haben wir einfach zu wenig Speicher. Erweitert man den Speicher, so verändert sich natürlich auch schnell das Verhältnis der „Committed Bytes in Use“ und wird sind wieder im grünen Bereich.
Committed Bytes
Die Committed Bytes geben an, wie viele Bytes durch verschiedene Prozessen zugewiesen und damit auf der Pageing-Datei reserviert wurden, aber vom Arbeitsspeicher noch nicht verarbeitet sind. Dieser Wert kann über den RAM Wert des Servers ansteigen und auch die dazugehörige Paging Datei würde damit anwachsen. Dieses Auslagern von zugesicherten Adressräumen für die Bytes auf die Festplatte nennt man Paging und friert den RAM für andere Aufgaben ein. Also je mehr Arbeit für den RAM zu verrichten ist, desto eher kann es zum Paging kommen, weil es einfach die Kapazität des Arbeitsspeichers übersteigt. Der „Freeze“ macht das ganze dann noch schlimmer. Daher sollten Sie darauf achten, dass die Committed Bytes immer unter 75% des physisch verfügbaren RAM Speichers liegen.
Free System Page Table Entries (PTEs)
Eine Seitentabelle wird vom Windows Virtual Memory Manager (VMM) genutzt, um die Zuordnung von virtuellen zu physischen Adressräumen zu organisieren. Wie bei den Committed Bytes angedeutet, hat jeder virtuelle Speicher auch eine entsprechende physische Zuordnung. Gibt es für neue Zuordnungen nicht genügend Seiten, muss gewartet werden, bis alte Zuorndungen abgearbeitet wurden und eine Seite wieder frei wird. Maximal 50.000 Seiten (ungefähr 195 MB) können allein für allgemeinen Operationen benötigt werden – und damit meine ich noch nicht einmal die Grundlast von Windows! Vor diesem Hintergrund wird schnell klar, dass weniger als 5.000 freie Seiten für PTEs ein Problem ist.
Pages/second
Dieser Counter referenziert zum Vorgang des “Paging”, also das Lesen oder Schreiben von Bytes auf die Festplatte aufgrund möglicher Ursachen, wie in Abschnitt für die Committed Bytes erwähnt. Ein Wert über 50 ist nicht optimal und sollte daher als Indikator aufgefasst werden, dass wir ein Arbeitsspeicherproblem haben. Ziehen Sie diesen Wert aber nicht als alleinige Messgröße für mangelhaften Speicher heran. Denn auch eine Applikation, die kontinuierlich aus einer Datei im Speicher liest, kann diesen Counter nach oben treiben. Sind also obige Counter niedrig, aber dieser sehr hoch, dann ist alles in Ordnung. Sind aber obige Counter nicht optimal, dann sind die „Pages/second“ ein zusätzlicher Beweis für mangelnden Arbeitsspeicher.
Available Mbytes
Zu guter letzt noch ein relativ einfacher Counter. Ist weniger als 5% des verfügbaren RAM Speichers frei, haben wir nicht genug davon und es kann zum „Paging“ kommen. Wie wir bei den Committed Bytes gelernt haben, wollen wir dies unbedingt verhindern. Erweitern Sie also den RAM, um wieder mehr freien Speicherplatz zu haben. *Hinweis: „Neuere“ SQL Versionen (ab 2008) sollten ein Minimum von 2 GB haben. Auch für das Betriebssystem selbst sollten immer mindestens 2 GB zur Verfügung stehen.
Viel Spaß beim „SharePointen“!
SharePoint Adventskalender – 12. Türchen
SharePoint Performance Monitoring – Performance Counter für System und Netzwerk
Performance Tuning – Performance Monitoring – Best-Practices für SP-SQL-Konfigurationen – BLOB Management – Backup & Recovery
Am letzten Tag für die SharePoint Performance Counter schauen wir uns zwei System und vier Netzwerk Messgrößen an. Die System-Indikatoren sind dabei zusätzliche Checks für den den Prozesser und die Netzwerkmessgrößen können – wie der Name schon sagt – einen möglichen Engpass am Netzwerk identifizieren.
System:
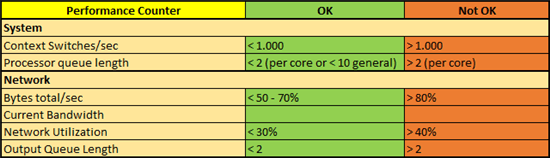
Context Switches/sec
Kontextwechsel treten auf, wenn der Prozessor zwischen zwei Threads wechselt. Dies kann z.B. geschene, wenn ein Thread, der eine höhere Priorität hat als der aktuell zu verarbeitende Thread hat, bereit für die Bearbeitung durch den Prozessor ist. Eine hohe Rate ist ein Zeichen dafür, dass sich viele gleichrangige Threads um die Bearbeitung im prozessor „streiten“.
Eine Anwendung (Application), besteht aus einem oder mehreren Prozessen. Ein Prozess ist einfach betrachtet das auszuführende Programm für die Anwendung. Also im Prinzip der Worker-Prozess (w3wp.exe) für SharePoint. Ein oder mehrere Threads, welche die Basiseinheit des Betriebssystems darstellen, die dem Prozessor zugeweisen werden können, laufen dann im Kontext eines Prozesses und erledigen die eigentliche Arbeit. In diesem Zusammenhang wird also deutlich, dass viele Kontextwechsel die Performance des Servers negativ beeinflusst. Obwohl auch ein Problem mit der Netzwerkkarte oder eines Gerätetreibers die Ursache für hohe Kontestwechsel sein können (siehe auch 9. Türchen über Privilege und User Mode Anfragen), so zeigt dieser Indikator auch auch, dass SharePoint einfach extrem viele Aufgaben abzuarbeiten hat, die der Prozesser nicht mehr bedienen kann. Ein Messwert von mehr als 1.000 Wechsel ist nicht optimal und deutet so ein Szenario an. Ein besserer Prozessor mit auch mehreren Kernen kann das Problem lösen.
Processor queue length
Prozessor-Warteschlangen entstehen, wenn neue Anfragen bereit sind, bearbeitet zu werden, aber die CPU aktuell mit noch anderen Anfragen voll beschäftigt ist. Ähnlich wie bei der Warteschlange, auf die Festplatten schreiben zu können (siehe 10. Türchen, Avg Disk Queue Length), ist bereits ein Wert von mehr also 2 (pro Kern) schlecht. Zufällig eintreffende Anfragen mit hoher Priorität oder unerwartet lang andauernde Threads können temporäre Warteschlangen entstehen lassen. Sind die Werte aber dauerhaft über dem Grenzwert, dann kann der Prozessor einfach nicht mehr alle Anfragen zeitnah abarbeiten. Die einfachste Lösung ist ein zweiter Server, den man in einem Load-Balancer Verbund dazu schaltet. Andere Ursachen können auch ein bestimmter „hängender“ Prozesse sein, ein schlechter Gerätetreiber mit vielen Kernerl-Mode Anfragen. Analysieren Sie also genau, welche Ursachen bei Ihnen eine dauerhafte Prozessor-Warteschlangen haben entstehen lassen.
Netzwerk:
Bytes total/sec
Dieser Indikator gibt an, wie viele Daten die Netzwerkkarte(n) insgesamt pro Sekunde verarbeiten, also die Summe aus erhaltenen und gesendeten Bytes. Ein dauerhafter Wert von mehr als 80% der angegebenen Kapazität der Netzwerkkarte, deuten auf einen Engpass hin. Ganz schnell kann man so nämlich am absoluten Limit sein und so verhindert die NIC (Network Interface Card), dass de Server sein volles Potential ausschöpfen kann. Achten Sie aber auch im Detail darauf, ob die Einzelgrößen, also nur das Empfangen oder nur das Senden, auffällig sind. Ein ein weiterer kleiner Tipp: Die NIC Kapazitäten werden in Bit angegeben, dieser Indikator wird hingegen in Byte gemessen.
Current Bandwidth
Diese Messgröße gibt einfach die geschätzte maximale Bandbreite der Netzwerkkarte an. Dies sollte der Kapazitätenangabe für die NIC entsprechen. Also eine NIC mit 1 Gbps sollte auch bei diesem Indikator genau diese 1 Gbps anzeigen. Ist dies geringer, haben Sie nicht bekommen, wofür Sie bezahlt haben.
Network Utilization
Bei der Netzwerknutzung kommen die ersten beiden Indikatoren zusammen. Sie stellt also die insgesamt verarbeiteten Bytes ins Verhältnis zur möglichen Bandbreite. Mehr als 40% Ausnutzung kann bereits nicht mehr optimal sein. Eine hohe Nutzung deutet nämlich an, dass viele Daten und Informationen verarbeitet und gesendet werden müssen. Geschicht dies im selben (Teil-) Netzwerk, so kann es zu Kollisionen kommen, wenn gleichzeit zwei Stationen eines Netzwerksegments versuchen, zu senden. Diese Paketkollisionen führe zu einer Verzögerung der Sendung, da ein erneuter Sendeversuch gestartet werden muss.
Die Grenzwerte sind hier aber mit Vorsicht zu genießen. Sind besipielsweise Server und Netze mit Switches und/oder Netzwerkbrücken verbunden, die auf einer höheren OSI-Ebene arbeiten, können gleichzeitig gesendete Pakete weitgehend minimiert werden. Denn in diesem Falle ist der Server meist direkt mit dem nächsten Switch verbunden und nur ein gleichzeitiger Sendeversuch dieser beider Stationen kann zu einer Kollision führen. Bei gleich hohen Sende- und Empgangswerten kann dies dennoch häufiger der Fall sein und dies ist schon mehrheitlich bei mehr als 40% Auslastung der Fall. Dedizierte Netzwerke, z.B. für Backup-Vorgänge, prinzipiell höhere Netzwerkkapazitäten aber auch Netzwerkkonfigurationen lösen dieses Problem.
Output Queue Length
Die Länge der Warteschlange für Datenpakete, die gesendet werden sollen, ist äquivalent zu den Warteschlangen bei Prozessor und Festplatte. Kommt es zu so einer Warteschlange, hat die Netzwerkkarte einfach nicht genug Leistung, um die zu sendenen Anfragen zeitnah abzuarbeiten. Auch hier ist ein dauerhafter Wert von über 2 nicht optimal.
Viel Spaß beim „SharePointen“!
SharePoint Adventskalender – 13. Türchen
SharePoint Configuration Best Practices – SQL Alias
Performance Tuning – Performance Monitoring – Best-Practices für SP-SQL-Konfigurationen – BLOB Management – Backup & Recovery
Einen fröhlichen 3. Advent wünsche ich! Die tief technischen Tipps für eine optimierte SharePoint Performance haben wir nun hinter uns gebracht. Heute und in den nächsten Tagen widmen wir uns ein paar Best Practices in Hinblick auf die Konfiguration von SharePoint und SQL.
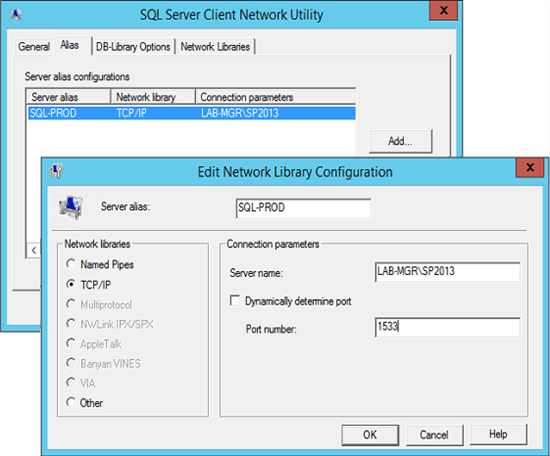
Beginnen wir mit einem einfachen Tipp – der SQL Alias. Wie wir wissen, gehört SharePoint und SQL einfach zusammen. Daher muss SharePoint immer wissen, wo sich seine Datenbanken befinden. Diese Referenz wird bei einer benamten Instanz mit „Servername\Instanzname“ angegeben. In einem SQL Cluster referenzieren wir natürlich den virtuellen Hauptknoten der verschiedenen SQL Nodes und den „Windows Listener“ bei einer SQL Always-On-Availability-Group.
Der Vorteil eines Alias ist die Möglichkeit, dass ich das Backend ändern kann, ohne große Konfigurationen am Frontend vornehmen zu müssen. Ist besipielsweise der SQL zu langsam geworden und soll auf einen neuen Server und/oder auf eine neue Instanz, dann muss ich nicht für jede Inhaltsdatenbank und jeden Service in SharePoint die neue Referenz setzen. Stattdessen passe ich nur einmalig den Alias an. Auch eine Änderung des Ports kann so ganz einfach erledigt werden.
Bitte achten Sie auch darauf, sollten Sie noch Systeme im 32bit-Modus haben, dass Sie den Alias sowohl für diese, also auch für die 64bit-Systeme setzen. Das Windows Tool „cliconfg.exe“ setzt für Sie den Alias. Dieses Tool finden Sie hier:
32bit-Mode:
C:\Windows\System32\cliconfg.exe
64bit-Mode:
C:\Windows\SysWOW64\cliconfg.exe
Ob die Einstellungen korrekt am System “angekommen” sind, können Sie in der Registry in folgenden Pfaden überprüfen:
32bit-Mode:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\MSSQLServer\Client\ConnectTo
64bit-Mode:
HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\Microsoft\MSSQLServer\Client\ConnectTo
Achten Sie außerdem darauf, dass Sie diese Einstellungen ebenso auf dem SQL machen, um sich auch von dort lokal mit einem Alias im SQL Management Studio mit der jeweilige Instanz verbinden zu können – dies können Sie auch direkt im SQL Configuration Manager erledigen.
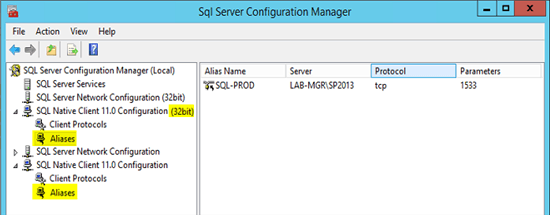
Zusammengefasst ist so ein Alias also ein extrem nützliches Werkzeug, um mögliche spätere Server-, Instanz- oder Portänderungen ohne viel Konfigurationsaufwand am zugehörigen SharePoint erledigen zu können.
Viel Spaß beim „SharePointen“!