

Learn more about how to secure your data with our free webinar “Protecting Sensitive Data in Office 365 at the Team and Data Levels.“
If you’ve been following things in the land of Microsoft 365, you will certainly have seen announcements about Project Cortex. It was first announced in November 2019 to “[apply] advanced artificial intelligence (AI) to empower people with knowledge and expertise in the apps they use every day.” Or in other words, Microsoft is investing in next-generation knowledge management to bring data, information, and records together across Microsoft 365 so it can be accessed, shared, and most importantly, used.
Records Managers everywhere are starting to drill deeper into what some of this advanced automation can actually mean for the industry. How can it be best used and what do we need to have in place to take advantage of some of this new and exciting technology coming our way?
In terms of practical application, Project Cortex has already released its first product: SharePoint Syntex. SharePoint Syntex is currently available for Microsoft 365 commercial customers and can be turned on in your tenant now.

SharePoint Syntex is exciting because it allows business experts to train the solution to understand content as well as they do. Let’s look at an example of what we could do with this in a records management context.
Using SharePoint Syntex
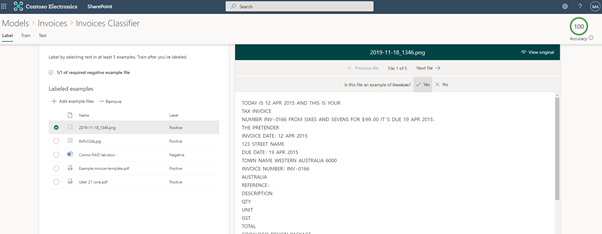
Let’s say your retention schedule says that you need to keep invoices for seven years and packing slips for three years. Or you need to keep an accident report form for 15 years, but a rehabilitation plan for five years. To ensure these invoices were classified and attached to the correct disposal class, we’d need to do something like separating where the invoices and packing slips are saved or ask our users to classify them individually as they get saved. Basically, we’d need to break up the information architecture or capture additional metadata, and neither of these are optimal solutions.
What we want to be able to do is have a flexible information architecture without end user burden. Advanced trainable classifiers like SharePoint Syntex allow us to do this. We can teach SharePoint Syntex to identify when something is an invoice or a packing slip or when something is an accident report or a rehabilitation plan with confidence. Once SharePoint Syntex recognizes the content based on how we have trained it, it will classify said content by setting it as a defined content type e.g. accident report or rehabilitation plan. You can also extract additional metadata to be attached to the content type as columns.
You can then extend your records management program with AvePoint Cloud Records. This solution allows you to build out business rules for information lifecycle or retention and disposal while building on the technology that Syntex provides. As business rules in Cloud Records can be based on content types and other metadata fields, it can take the output provided by Syntex and automatically assign the correct records classification and associated retention/disposal outcomes.
When it comes to overall design, SharePoint Syntex’s capabilities could mean less pressure on your information architecture and, more importantly, less pressure on your end users. This is because they will get the added benefit of good metadata without the burden of having to apply it manually.
While these advanced automated intelligence engines are amazing innovations that can be utilized for great benefit in the RM world, unfortunately, they are still not the silver records management bullet we all so desperately would like.
These advanced tools still need to know what you want them to do. For example, I could ask a search engine to show me a picture of food. That search engine is going to come back with a huge variety of different types of food. There will be millions and millions of pictures. The search engine couldn’t know that I wanted it to show me a picture of some aged cheddar cheese (mmmm cheese) because I was too general in my initial ask. We still have to be specific about what our desired outcome is and we need to have a plan for how to get there.

3 Useful Tips
If you’re thinking about SharePoint Syntex and how this could work in your organisation, here are three things to remember:
- Start small. Pick up a subset of information that lends itself to auto-classification (that is, things that are easily repeatable for the machine to find, templates, etc.) and then think about the outcome you want to get to. Starting small and simple will allow you to test what really works for your process and your organisation. This is a good opportunity to learn before rolling out any further.
- Engage with your business areas. It’s their knowledge you are wanting to try and get the machine to replicate so they can concentrate on other things. What will be most valuable to them? What will help to make their lives better?
- Refine and refine again. Like any new thing it’s not going to be perfect on the first try, but by refining and revising you’ll be able to get some great automation outcomes.
There is simply too much data and information for us as Records Managers to oversee in the ways that we used to. We need to take advantage of the automation tools that are coming to the market that can assist us in getting to the outcome that we need, but without the user burden or RM manpower that we just don’t have.
There is a myriad of ways that automated intelligence can support records management outcomes and the only way to found out more is to get in and try!



